





I. 서 론
광대역 통신, 차세대 레이다, 전자전(EW: electronic warfare), 신호 정보(SIGINT: signal intelligence)와 같은 다양한 응용 분야에서는 광대역 주파수 범위에 걸쳐 일관된 시스템 성능을 유지하는 것은 매우 중요하다[1]. 안테나 배열을 사용하는 수신기 시스템에서, 일관된 공간 필터링 능력과 수신 감도를 보장하여 전체적인 신뢰성을 높이기 위해서는 주파수 변화와 관계없이 일정한 빔 폭과 이득을 유지하는 주파수 불변(frequency-invariant) 빔 패턴을 형성하는 것이 필요하다[2].
그러나 고정된 기하학적 구조를 갖는 기존 배열 시스템은 물리적 제약으로 인해, 주파수가 높아질수록 유효 개구면이 확장되어 빔 폭이 좁아지는 현상이 발생한다. 빔 스퀸트(beam squint)라 불리는 이 현상은 광대역 신호 수신 시 공간적 왜곡을 일으키며, 특정 대역에서 원치 않는 간섭을 허용하거나 목표 신호의 수신 품질을 저하시키는 원인이 된다[3]. 이를 해결하기 위해 중첩 배열(nested arrays)[4], 로그-주기 배열[5], 필터-합계 빔포머[6] 등의 기법이 제안되었으나, 하드웨어 복잡도 증가나 제한적인 운용 대역폭 등의 한계가 존재한다. 또한, GSC(generalized sidelobe canceller)[7]나 부대역 처리 기법[8]과 같은 해석적 접근 방식은 이상적인 채널 환경을 가정하므로, 상호 결합(mutual coupling)이나 소자 위치 오차 등 비선형적 왜곡이 존재하는 실제 하드웨어 환경에서는 성능이 제한될 수 있다.
최근 복잡한 최적화 문제를 해결하기 위한 대안으로 머신러닝이 대두되고 있으나[9],[10], 대부분의 연구는 협대역 환경에 국한되어 있다. 특히 시뮬레이션 환경에서 학습된 모델을 실제 환경에 적용할 때 발생하는 도메인 격차(domain gap)를 해소하는 것은 광대역 빔포밍 분야의 주요 난제이다.
이에 본 논문에서는 광대역 안테나 시스템의 빔 스퀸트 현상을 억제하고, 하드웨어 불완전성이 존재하는 실제 환경에서도 강인한 주파수 불변 균일빔을 생성하기 위한 데이터 기반 설계 프레임워크를 제안한다. 제안하는 기법은 지도 학습(SL: supervised learning), 비지도 학습(UL: unsupervised learning), 강화 학습(RL: reinforcement learning) 모델을 포괄적으로 활용하며, 시뮬레이션 데이터로 사전 학습(pre-training)된 모델을 실제 야외 방사 테스트 데이터로 미세 조정(fine-tuning)하는 전이 학습 기법을 적용하여 실용성을 극대화하였다.
본 논문의 구성은 다음과 같다. II절에서는 시스템 모델과 시뮬레이션 및 실제 데이터 획득 과정을 설명하고, III절에서는 제안하는 세 가지 학습 모델(SL, UL, RL)의 구조와 학습 방법을 상세히 기술한다. IV절에서는 시뮬레이션 및 야외 실험 결과를 통해 제안 기법의 성능을 이론적 LCMV(linearly constrained minimum variance) 빔포머와 비교 분석하며, 마지막으로 V절에서 결론을 맺는다.
II. 시스템 모델 및 데이터 획득
본 논문에서는 광대역 스펙트럼에서 작동하도록 설계된 Nr개의 안테나 소자를 갖춘 수신기 시스템을 고려한다. 핵심 과제는 이 Nr개 소자로부터의 신호를 처리하여 주파수 변화와 무관하게 일관된 빔 패턴을 형성하는 것이다. 기계 학습의 성공적인 적용은 훈련 데이터의 품질과 구조에 결정적으로 의존한다. 본 절에서는 제안된 모델의 훈련 및 검증에 사용되는 데이터 생성 및 보정 프레임워크를 설명한다.
초기 모델 훈련을 위해 충분히 크고 다양한 데이터셋을 확보하기 위해, 먼저 시뮬레이션 된 훈련 샘플을 생성한다[11]. 가능한 모든 환경 조건을 포괄하는 포괄적인 실제 신호 세트를 수집하는 것은 비현실적이기 때문에 이 과정은 필수적이다. Nr개의 안테나 소자, Nf개의 이산 주파수 빈, Nθ개의 잠재적 도달 각도(DOA : direction of arrival)를 나타내는 Nr×Nf×Nθ차원의 시뮬레이션 데이터 큐브가 생성된다. 이 훈련 샘플들은 무작위 신호의 도래 방위각, 다양한 간섭원 및 다양한 잡음 레벨을 고려하여 광범위하게 시뮬레이션된 신호 대 간섭 잡음비(SINR: signal to interference plus noise ratio) 조건하에서 생성된다.
시뮬레이션 데이터와 실환경에서의 수집 데이터 사이의 간극을 메우고 모델이 하드웨어적 불완전성 및 실제 채널 효과에 강인하도록 보장하기 위해, 보정 및 미세 조정 과정이 필수적이다[12].
첫째, 내부 보정 절차가 수행된다. 보정 신호 생성기가 작동 대역 전반에 걸쳐 알려진 진폭과 위상의 신호를 주입한다. 수신기는 Nf개의 주파수 지점에서 Nr개 각 채널의 채널별 오프셋을 측정하고, 결과를 Nr×Nf 차원의 보정 데이터 행렬에 저장한다. 이 행렬은 이후 수신되는 모든 신호를 보정하여 채널 간 불일치를 최소화하는 데 사용된다.
둘째, 이렇게 보정된 실제 신호가 수집된다. 다중 경로 페이딩 및 주변 간섭과 같은 환경적 영향을 본질적으로 포함하는 이 샘플들은 사전 훈련된 기계 학습 모델을 미세 조정(fine-tuning)하는 데 사용된다. 시뮬레이션 데이터로 사전 훈련하고 보정된 실제 데이터로 미세 조정하는 접근 방식은 강인하고 실용적인 시스템을 개발하는 데 매우 중요하다. 전이 학습(transfer learning)과 같은 기술이 사전 훈련된 모델을 새롭거나 동적인 작동 환경에 효율적으로 적응시키는 데 사용될 수 있다[13].
III. 광대역 주파수 불변 균일빔 생성
기존 빔포밍 수신기의 출력은 가중치 벡터 w가 적용되는 선형 연산이다. 선형 제약 최소 분산(LCMV) 알고리즘은 원하는 신호 방향으로 빔을 조향하면서 특정 간섭 방향으로 널(null)을 위치시킬 수 있기 때문에 이러한 가중치를 결정하는 데 자주 사용된다[14].
본 연구에서는 시스템 모델을 주파수 영역에서 정의한다. 주어진 방위각 θ와 주파수 f에 대한 배열 조향 벡터(steering vector)를 이라 하자. 소자 간격이 d인 등간격 선형 배열(ULA: uniform linear array)의 경우, n번째 소자의 응답은 식 (1)과 같이 정의된다.
주파수 f에서의 수신 신호 벡터 은 식 (2)와 같다.
여기서 θs와 θk는 각각 원하는 신호와 k번째 간섭 신호의 방위각 정보이고, Nint 는 간섭 신호의 수이며, s(f), ik(f), n(f)는 각각 신호, 간섭, 잡음의 주파수 영역 표현이다. 빔포머 출력은 y(f)=wHx(f)로 주어지며, 여기서 w는 우리가 찾고자 하는 단일의 주파수 불변 균일빔 가중치 벡터이다. 결과적인 전력 빔 패턴은 식 (3)과 같다.
광대역 주파수 불변 균일 빔포밍의 목표는 모든 f∈[fmin,fmax]에 대해 빔 패턴 B(θ,f | w)가 일정하게 유지되는 단일 가중치 벡터 w를 찾는 것이다. 특정 주파수 f에서 신호 대 간섭 잡음비(SINR)를 최대화하는 LCMV 해는 식 (4)와 같다.
여기서 는 주파수 f에서의 공분산 행렬이다. 또한 C는 원하는 신호 방향과 널 방향에 해당하는 조향 벡터들로 구성된 제약 행렬이며, f는 각 방향에 대한 빔포머의 목표 이득을 정의하는 응답 벡터이다. 이와 같은 방법으로 얻어지는 가중치 벡터는 주파수에 의존적이므로, 이를 광대역 주파수 범위에 직접 적용하면 빔 스퀀트(beam squint) 현상이 발생한다. 본 논문은 기계 학습을 사용하여 단일의 최적 w를 생성함으로써 이러한 한계를 극복한다.
본 절에서는 공동 손실(joint loss) 최적화 프레임워크를 사용하는 지도 학습 접근법을 제안한다(그림 1). 제안방식으로 생성되는 빔포머는 (1) 높은 SINR 성능과 (2) 주파수 불변 균일빔 형태라는 잠재적으로 상충하는 두 가지 목표를 동시에 만족시켜야 한다.
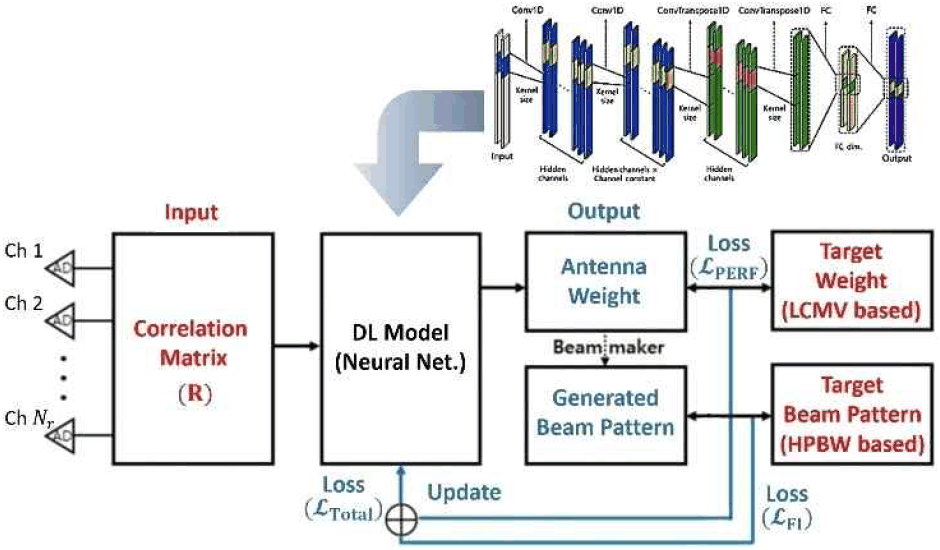
지도 학습 모델은 4개의 1D 합성곱 층(1D-CNN)과 2개의 완전 연결(FC) 층으로 구성된 아키텍처를 가지며, 활성화 함수로는 GELU(Gaussian error linear unit)가 사용된다. 모델 fNN (· ; Θ)은 환경 데이터 X(예: 중심 주파수에서의 공분산 행렬 R(fc))를 입력으로 받아 최적의 주파수 불변 균일빔 가중치 벡터 ŵ을 예측한다. 이 모델은 성능 손실 함수 ℒPERF와 주파수 불변성 손실 함수 ℒFI의 가중 합인 총 손실 함수 ℒTotal을 최소화함으로써 훈련된다.
이 손실 함수는 예측된 가중치가 높은 SINR을 달성하도록 유도한다. 기준 주파수 fc에서의 최적 LCMV 가중치 wref,i=wLCMV (Ri (fc))를 목표값으로 사용하며, M개의 훈련 샘플에 대한 평균 제곱 오차(MSE: mean squared error)로 정의된다.
비지도 접근법은 주로 고차원 입력 데이터를 특성화하는 데 사용된다(그림 2). 본 연구에서는 입력 신호 환경의 압축된 저차원 표현을 학습하기 위해 오토인코더(autoencoder)를 사용한다.
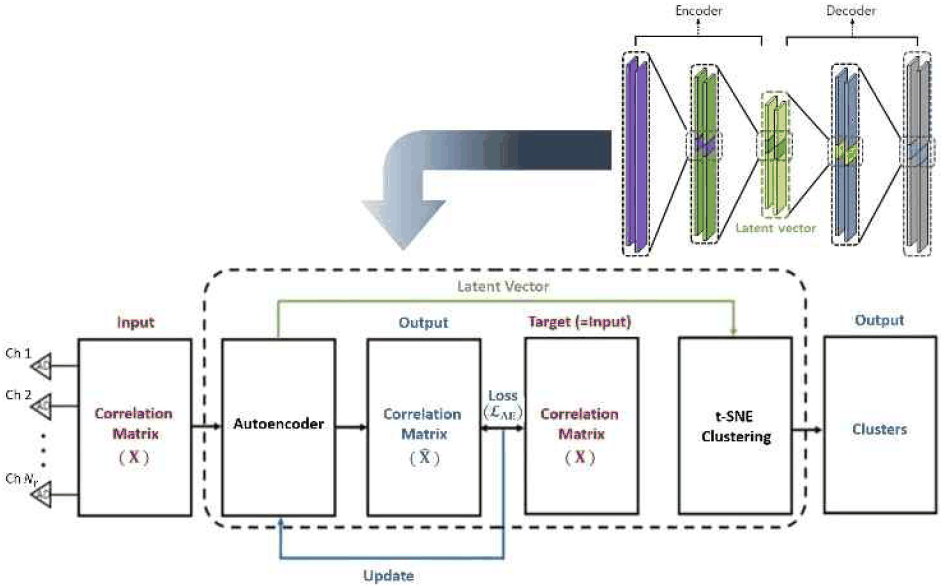
오토인코더는 인코더 E(· ; ΘE)와 디코더D(· ; ΘD)로 구성된다. 인코더는 입력 X(예: 공분산 행렬 )를 잠재 벡터 z=E(X ; ΘE)로 매핑하고, 디코더는 z로부터 입력을 식 (8)과 같이 재구성한다.
모델은 M개의 훈련 샘플에 대해 Frobenius norm을 사용하여 정의된 재구성 오류를 최소화함으로써 훈련된다.
오토인코더 아키텍처는 인코더와 디코더 각각 2개의 FC 층으로 구성되며, GELU 활성화 함수를 사용한다.
훈련 후, 인코더 E(·)는 강력한 특징 추출기 역할을 한다. 훈련 데이터를 인코더에 통과시켜 얻은 잠재 벡터 z들은 t-SNE(t-distributed stochastic neighbor embedding)[15]를 통해 시각화된다. 이 분석은 데이터의 기저 구조를 드러내어, 유사한 신호 환경(예: 특정 도래 방위각 또는 간섭 패턴)에 해당하는 클러스터를 식별하는 데 사용된다. 나아가, 훈련된 디코더 D(·)는 학습된 잠재 공간 내에서 샘플링하거나 보관함으로써 새로운 빔포밍 환경을 합성할 수 있는 생성 모델로 활용될 수 있다.
강화 학습 프레임워크는 신경망 구조의 종류 및 하이퍼파라미터를 탐색하는 NAS(neural architecture search) 기법을 구현하기 위해 사용된다(그림 3). 이를 통해 학습형 모델이 주어진 데이터와 목적에 맞는 최적의 모델을 스스로 디자인하여 향상된 성능의 균일 합성빔 생성이 가능하다.
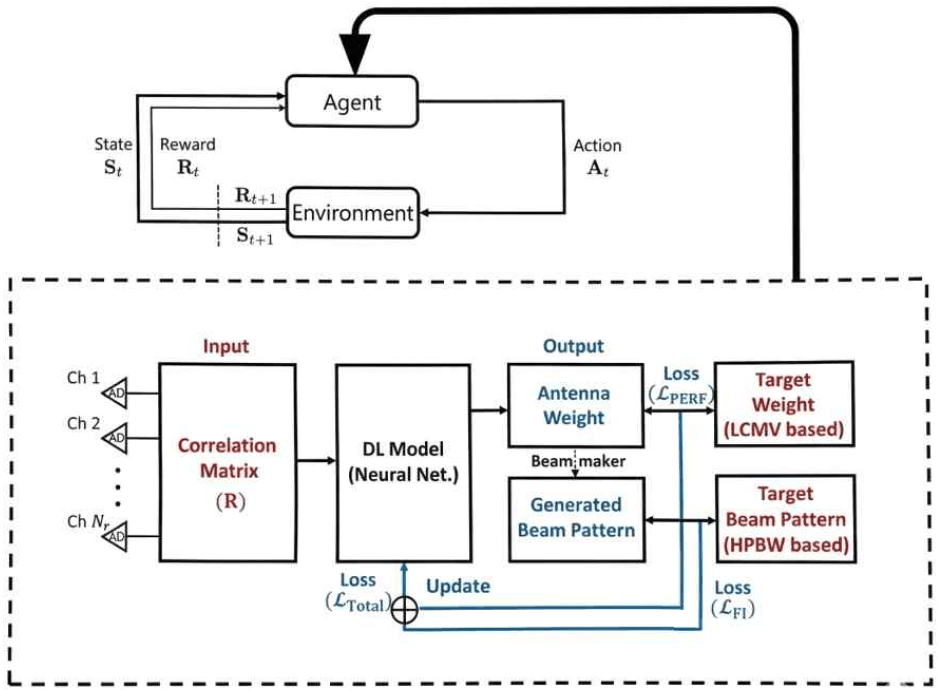
본 연구에서는 최적의 신경망 구조 탐색 과정을 마르코프 결정 과정(MDP: Markov decision process)으로 모델링하며, 이는 상태(state), 행동(action), 보상(reward)으로 정의된다.
t 시점에서의 상태 St는 현재 선택된 하이퍼파리미터 조합 λt와 해당 모델의 검증 데이터셋 Dval에 대한 총 손실 값 ℒval(λt)으로 정의된다.
이때 Θ*는 하이퍼파라미터 λt를 적용하여 훈련 데이터셋으로 학습이 완료된 모델의 파라미터이며, Dval은 훈련 데이터와 상호 배타적(mutually exclusive)인 검증용 샘플들의 집합을 의미한다.
에이전트(agent)는 현재 상태를 기반으로 탐색 공간 Λ 내에서 다음 시도할 하이퍼파라미터 조합 λt+1을 결정한다. 탐색 공간은 학습률, 커널 크기, 레이어 수 등을 포함한다.
보상은 에이전트가 선택한 행동이 목표 성능을 얼마나 만족시켰는지를 평가한다. 본 연구에서는 식 (7)에서 정의한 총 손실 함수 ℒTotal의 음의 값을 보상으로 설정하여, 손실을 최소화하는 것이 보상을 최대화하는 것과 같도록 한다.
강화 학습의 목표는 누적 보상의 기댓값을 최대화하는 최적의 하이퍼파라미터 λ*를 찾는 것이다.
여기서 γ는 할인 인자(discount factor)이다. 이러한 과정을 통해 모델은 주어진 데이터 환경에서 빔 패턴의 주파수 불변성과 SINR 성능을 동시에 극대화하는 최적의 네트워크 구조를 스스로 학습하게 된다. 실제 구현에서는 Optuna 라이브러리의 TPE(tree-structured Parzen estimator) 알고리즘[16]을 사용하여 위 최적화 문제를 해결한다. 강화 학습의 ‘environment’는 전체 하이퍼파라미터 공간을 의미하고, ‘agent’는 최적의 파라미터를 탐색하는 신경망 모델 자체이며, 매 시행마다 도출된 결과값과 조합을 테스트하여 최적의 균일빔 성능을 획득한다.
IV. 성능 결과
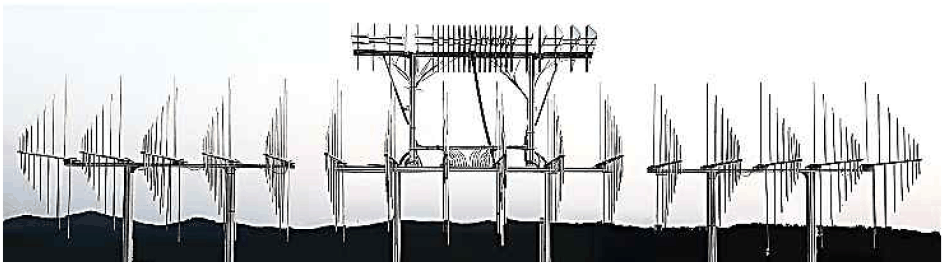
제안된 기계 학습 프레임워크를 검증하기 위해, 모델링 및 시뮬레이션과 실제 야외 방사 시험을 모두 활용하여 광범위한 평가를 수행하였다. 실험 구성에는 관심 주파수 대역인 저대역, 중대역, 고대역을 모두 커버하도록 설계된 광대역 안테나 배열가 사용되었다. 그림 4에 나타난 바와 같이, 구조물 상단에 위치한 중/고대역 안테나는 기존의 균일 간격 배열(uniformly spaced array) 대신 스케일드 개구면(scaled aperture) 설계를 채택하였다. 균일빔 생성을 위한 실 데이터 획득 및 검증을 위하여 활용된 광대역 안테나 배열 테스트베드의 물리적 사양은 표 1과 같다.
모든 모델의 핵심 목표는 전체 운용 대역에 걸쳐 20°의 일정한 목표 반전력 빔폭을 유지하는 것이다. 성능은 20° 목표값에 대한 반전력 빔폭의 평균 제곱근 오차(RMSE: root mean square error)와 모의 수신 시나리오에서의 비트 오류율(BER: bit error rate)을 통해 정량화하였다.
제안된 데이터 기반 접근법의 하드웨어 효율성을 검증하기 위해 Intel Xeon 69226R CPU와 총 624 TFLOPs의 연산 능력을 보유한 2기의 NVIDIA A100 GPU 환경에서 분석을 수행하였다. 모든 모델은 역행렬 연산을 수행하는 기존 LCMV 기법과 달리, 학습된 단일 가중치 벡터를 즉각적으로 산출하여 연산 복잡도를 획기적으로 낮추었다. 표 2는 각 모델별 연산량(FLOPs), 추론 시간, 학습 시간, 파라미터 수 복잡도를 비교한 내용으로, 2개 층의 완전 연결(FC) 레이어로 구성된 비지도 학습(UL) 모델은 약 0.07 MFLOPs의 매우 낮은 연산량으로 0.01 ms 이내의 추론 시간을 달성하였다. 지도 학습(SL) 모델은 4개의 1D-CNN 층을 활용한 공간 특징 추출 과정으로 인해 약 1.2 MFLOPs의 연산량을 보였으나, 이 역시 실시간 시스템 운용에 충분한 수준이다. 강화 학습(RL)의 경우, 주어진 데이터 환경에 최적화된 하이퍼파라미터 조합을 스스로 탐색하는 NAS 과정에서 약 24시간 이상의 높은 학습 비용이 소요되었으나, 최종 도출된 모델은 추론 단계에서 매우 높은 연산 효율성을 유지하며 광대역 주파수 불변 특성을 성공적으로 확보하였다.
그림 5~그림 7은 각각 지도 학습(SL), 비지도 학습(UL), 강화 학습(RL) 모델을 통해 생성된 빔 패턴을 보여준다.
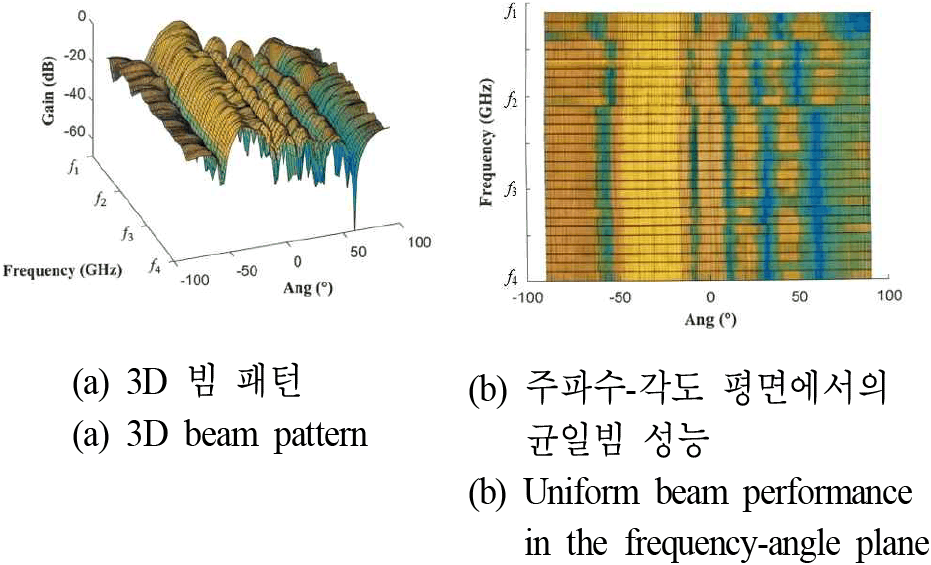
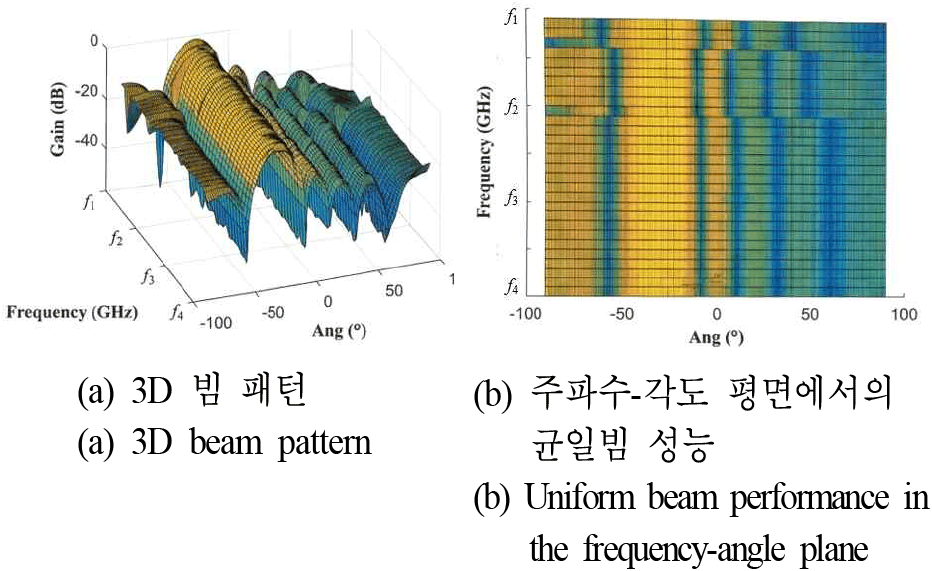
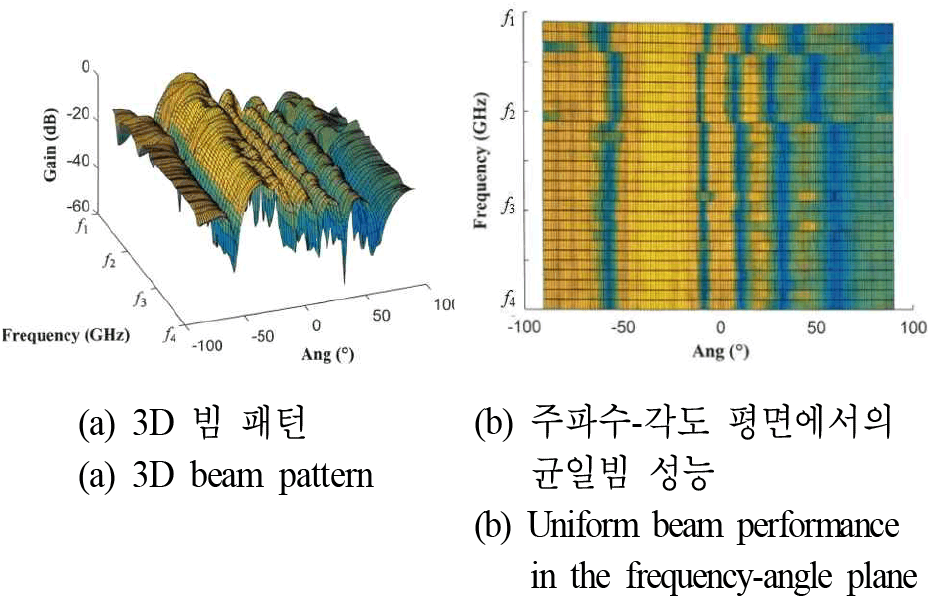
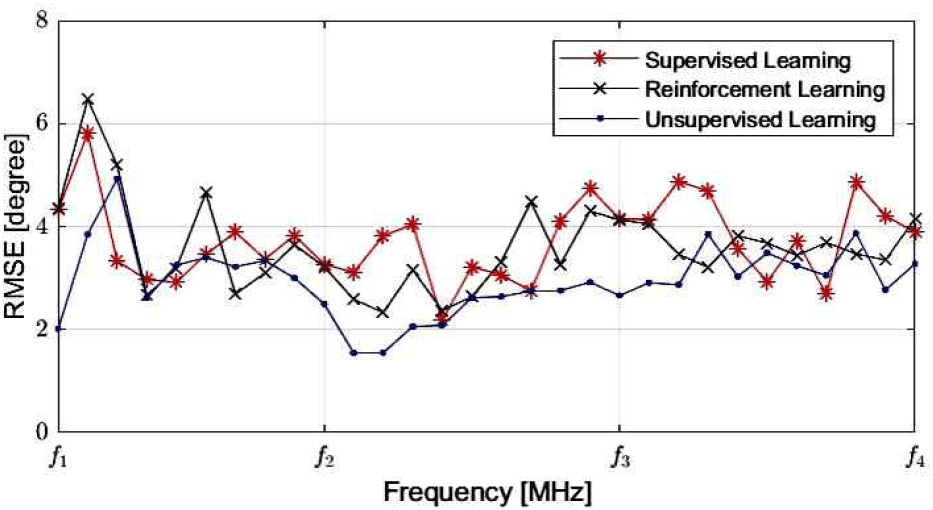
세 가지 접근법 모두 전체 운용 주파수 대역(fmin~fmax)에서 주파수 변화에 따라 빔폭이 좁아지는 빔 스퀀트 현상을 효과적으로 억제하고 있음을 시각적으로 확인할 수 있다. 특히, 목표 조향 각도인 −30° 방향에서 주파수와 무관하게 일정한 메인 빔폭을 형성하고 있으며, 이는 제안된 머신러닝 기반 프레임워크가 광대역 주파수 불변 빔포밍 가중치 벡터를 성공적으로 도출했음을 의미한다. 지도학습, 비지도학습, 강화학습에 따른 균일빔 생성시 목표 반전력 빔폭(HPBW) 20°에 대한 균일빔 생성 결과를 비교하기 위하여 그림 8과 같이 주파수별목표 균일빔 폭에 대한 RMSE 값을 제시하였다.
모의 수신 시나리오에서의 모델별 비트 오류율 성능을 그림 9~그림 11을 통하여 확인하였다. 이는 그림 4를 통하여 제시된 안테나 배열을 적용하여 모든 운용 주파수 대역(fmin~fmax) 및 방위각(−5°~55°)에 대하여 균일빔 또는 LCMV를 적용했을 경우 비트 오류율 성능을 반영한 결과이다.
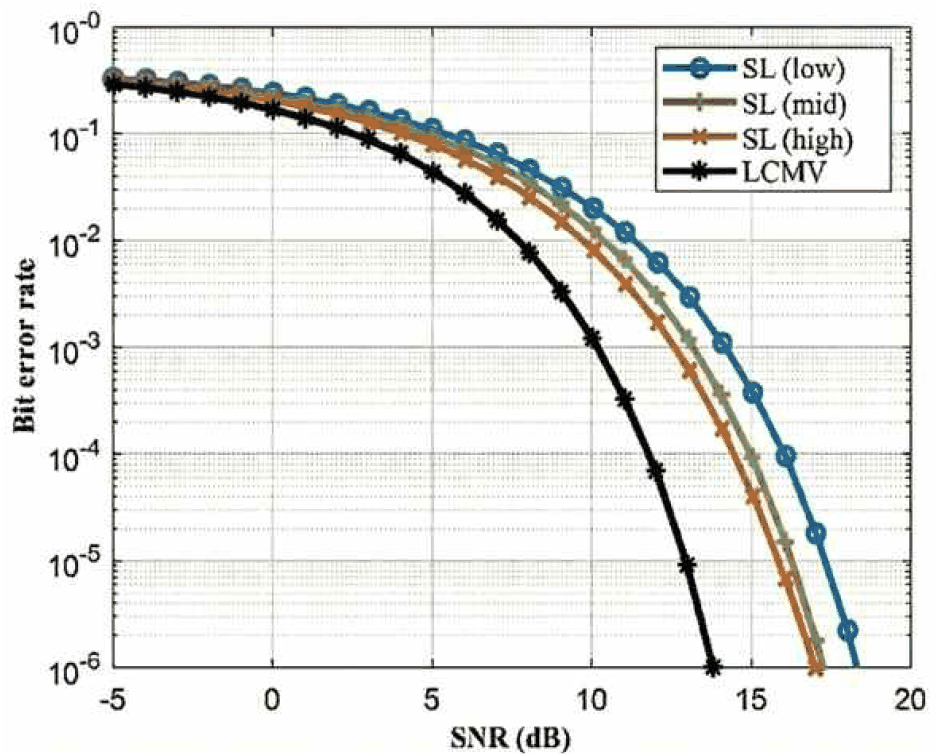
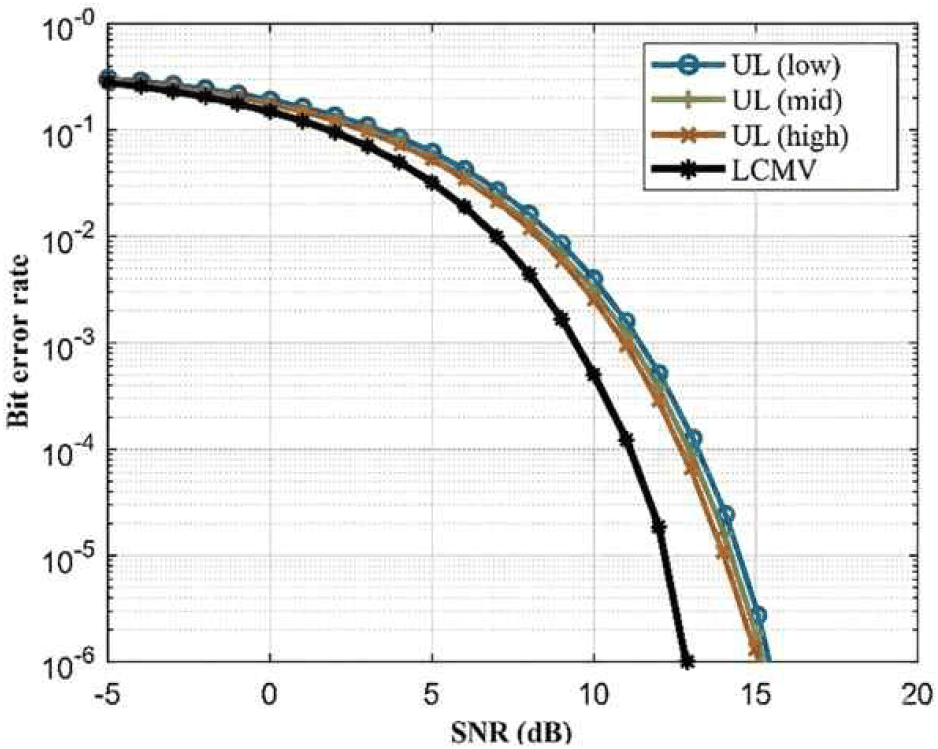
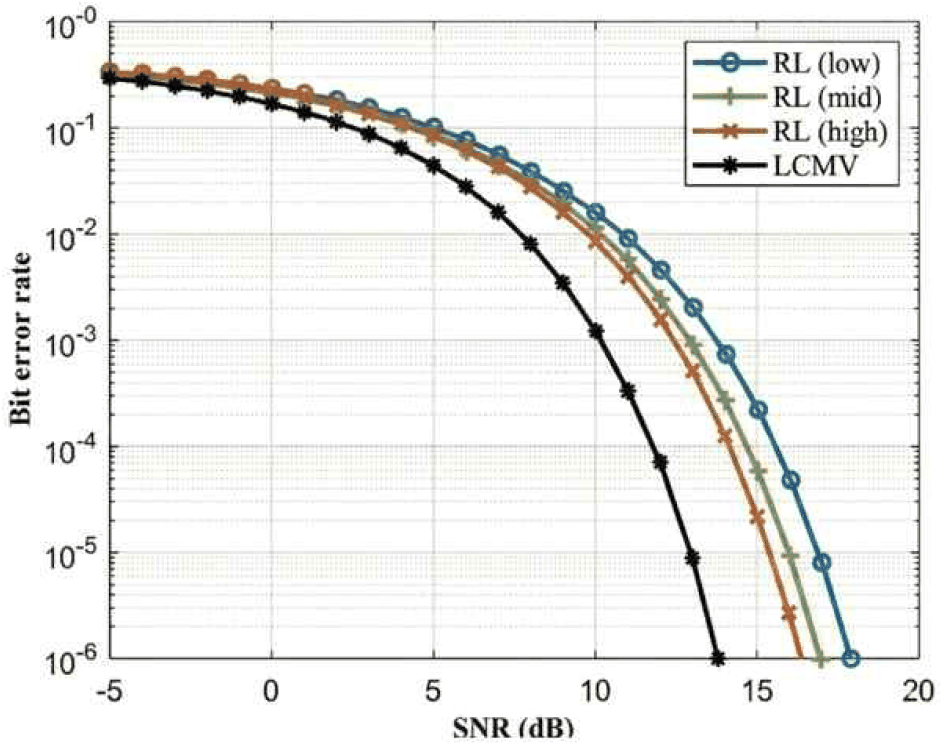
주파수 불변 빔포밍은 빔폭을 일정하게 유지하는 제약 조건으로 인해, 이론적으로 최대 SINR을 추구하는 일반적인 LCMV 빔포머 대비 수신 성능의 손실이 발생할 수 있다. 그러나 그림 9~그림 11에 나타난 비트 오류율 성능 곡선을 살펴보면, 제안된 세 가지 학습 모델 모두 이론적인 LCMV 성능 곡선(검은색)을 밀접하게 추종하는 것을 확인할 수 있다.
지도 학습(SL) 모델은 저대역(low), 중대역(mid), 고대역(high) 모두에서 LCMV와 유사한 BER 감소 추세를 보이며, 빔 형상 유지와 수신 성능 간의 균형을 잘 맞추고 있음을 그림 9를 통하여 보여준다. 그림 10의 비지도 학습(UL) 모델 또한 전 대역에서 LCMV 성능에 근접한 결과를 나타내며, 특히 높은 SNR 영역에서도 성능 저하가 최소화됨을 확인할 수 있다. 그림 11에서 강화 학습(RL) 에이전트에 의해 최적화된 모델 역시 전체 대역에서 안정적인 통신 성능을 보장하며, 이는 보상 함수 설계를 통해 빔 패턴의 균일성과 SINR 성능을 동시에 최적화한 결과로 해석된다.
종합적으로, 제안된 데이터 기반 접근법들은 광대역 환경에서 빔 패턴의 주파수 불변성을 확보함과 동시에, 통신 시스템이 요구하는 신뢰성 있는 수신 성능을 만족시키는 것으로 확인되었다.
정량적인 성능 평가는 표 3의 시뮬레이션 결과와 표 4의 야외 방사 테스트 결과를 통해 분석할 수 있다. 목표 반전력 빔폭(HPBW: half power beam width)인 20°에 대한 RMSE를 측정한 결과, 시뮬레이션 환경(표 3)에서는 비지도 학습(UL) 모델이 전체 대역 평균 RMSE 3.43°로 가장 우수한 주파수 불변성을 보였다. 이는 오토인코더가 입력 신호 환경의 잠재적 특징을 효과적으로 압축 및 학습하여 빔 형성의 안정성을 높인 것으로 분석된다. 실제 야외 방사 테스트(표 4)에서는 하드웨어의 불완전성과 채널 환경의 영향으로 인해 시뮬레이션 대비 오차가 다소 증가하였으나, 세 가지 모델 모두 전체 대역에서 약 5.5°~5.7° 수준의 균일한 RMSE 성능을 기록하였다. 이는 시뮬레이션 데이터로 사전 훈련된 모델을 보정된 실제 데이터로 미세 조정(fine-tuning)하는 과정이 실환경에서의 성능 열화를 방지하는 데 효과적이었음을 시사한다.
| Generating model | Low band | Mid band | High band | Total |
|---|---|---|---|---|
| Supervised learning | 4.77 | 4.06 | 4.28 | 4.28 |
| Unsupervised learning | 4.17 | 3.75 | 3.17 | 3.43 |
| Reinforcement learning | 5.38 | 3.67 | 3.93 | 4.03 |
| Generating model | Low band | Mid band | High band | Total |
|---|---|---|---|---|
| Supervised learning | 5.53 | 6.19 | 5.03 | 5.54 |
| Unsupervised learning | 5.36 | 6.41 | 4.87 | 5.57 |
| Reinforcement learning | 5.62 | 6.55 | 5.08 | 5.74 |
V. 결 론
본 논문에서는 광대역 안테나 시스템의 빔 스퀀트 현상을 해결하기 위해 지도, 비지도, 강화 학습 기반의 주파수 불변 빔포밍 설계 프레임워크를 제안하였다. 이 접근법은 시뮬레이션 데이터를 통한 사전 학습과 보정된 실제 데이터를 활용한 전이 학습을 결합하여, 하드웨어적 불완전성이 존재하는 실제 운용 환경에서도 강인하게 작동하도록 설계되었다.
성능 평가 결과, 제안된 세 가지 모델 모두 시뮬레이션 및 야외 방사 테스트 전반에서 목표 빔폭(20°)을 효과적으로 유지하며 약 5.5°~5.7°의 균일한 RMSE 성능을 달성하였다. 아울러 이론적인 LCMV 빔포머의 비트 오류율 곡선을 밀접하게 추종함으로써, 빔 형상의 균일성 유지와 통신 수신 성능 간의 트레이드오프를 성공적으로 최적화했음을 입증하였다.


