





Ⅰ. 서 론
전자전(electronic warfare) 환경에서는 전파 방해(jamming)나 기만(deception) 등을 위해 레이다(radar) 신호를 빠르고 정확하게 분석할 필요가 있다[1],[2]. 레이다는 신호의 주파수(radio frequency: RF), 펄스 반복 간격(pulse repetition interval: PRI), 펄스 폭(pulse width: PW) 등의 범위와 시간적인 변화 형태를 특성으로 가진다. 이러한 레이다 신호를 분석하기 위해 초기에는 사전에 구축된 신호 정보의 데이터베이스를 이용했지만[3], 최근에 심층학습을 적용한 방법들이 제시되고 있다. 심층학습은 CNN (convolutional neural network)[4]~[7] 또는 LSTM(long short-term memory) 모델[1],[8]을 주로 사용하며, 대부분 PRI, RF, PW 등의 범위와 변화 형태와 같은 펄스 레이다 신호의 특징별로 수~수십 가지로 신호를 분류한다. 한편, 참고문헌 [9]에서는 펄스 레이다 신호를 분석하기 위해 펄스 신호의 주요한 특성인 무선주파수와 펄스 반복 간격의 시간적인 변화 형태를 각각 7가지, 8가지로 구분하고, 변화 형태별로 속성을 정의한 후, LSTM을 사용하여 변화 형태와 속성을 식별하는 방법을 제시하였다. 속성으로는 각 변화 형태에 대해 한 주기 내에 체류하는 계단(dwell) 개수와 한 계단 내의 펄스 개수로 정의하였으며, 한 주기가 최대 32개의 펄스로 구성된다고 가정하였다. 그러나 일반적으로 체류변경(dwell and switch: D&S)의 변화 형태는 그 최대 주기가 수백에 이르며, 이것은 LSTM의 입력 데이터 길이를 확대시키는 것에 해당한다.
LSTM은 입력 데이터 길이의 제곱에 비례하여 내부 파라미터(즉 계수) 수가 증가하는 특성이 있다[9]. 이 경우,긴 데이터를 그대로 LSTM에 입력하는 방법은 학습 시간이 오래 걸릴 뿐만 아니라, 계수의 개수가 과도하게 많아져 분류 성능이 오히려 저하된다[4].
이 논문에서는 LSTM의 이러한 단점을 극복하고 긴 주기를 가지는 체류변경 형태까지 식별할 수 있도록 CNN과 LSTM이 결합된 분류기를 제시하고자 한다. CNN은 입력이 특정 패턴 또는 패턴의 변환을 포함하는 경우, 우수한 성능을 나타내는 것으로 알려져 있다[1]. 제시 방법에서는 CNN을 사용하여 긴 주기 데이터로부터 짧은 길이의 압축된 특징을 추출한다. 이 특징 데이터를 LSTM에 적용함으로써 최대 256개 펄스로 구성된 긴 주기 데이터를 분류할 수 있다.
Ⅱ. 펄스 레이다 신호의 속성 정의
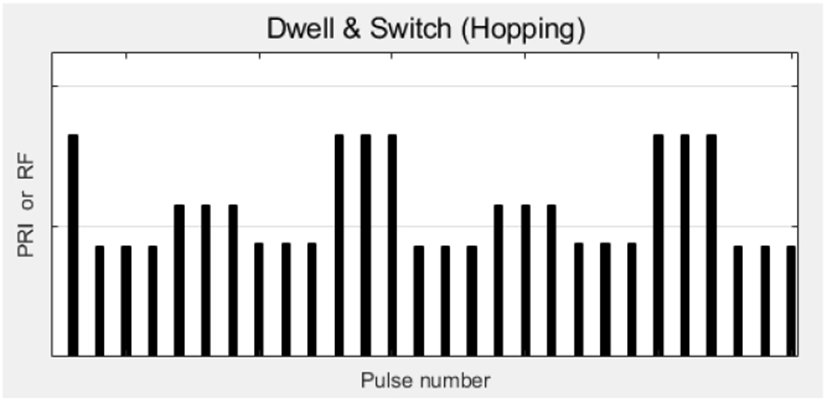
이 논문에서 식별하고자 하는 펄스 레이다 신호는 참고문헌 [9]에서와 같이 각 펄스의 RF와 PRI가 각각 7가지와 8가지 형태 중의 하나로 변한다고 가정한다. 또, 변화 형태(type)와 변화 주기당 체류 계단 수(nSW), 한 계단 내의 펄스 수(nDW)를 레이다 펄스 신호의 속성으로 정의한다(표 1 참조). 그림 1은 nSW=4, nDW=3, 주기 12인 체류변경 형태의 예를 나타낸다. 주기가 없는 고정(STA/ Fix) 형태는 nSW, nDW 모두 1로 놓고, 고정 및 체류변경을 제외한 나머지 형태는 nDW를 1로 놓는다.
체류변경 형태의 nSW, nDW 속성값은 비교적 큰 값을 가질 수 있으므로 다음 조건의 범위에 있다고 가정한다.
식 (1)은 RF와 PRI의 최대 주기가 256임을 의미하며, 이러한 가정은 실제 펄스 레이다 신호에서 나타나는 값을 기준으로 설정하였다. 체류변경을 제외한 나머지 변화 형태는 참고문헌 [9]와 동일하게 최대 주기를 32로 놓았으며, 스태거(stagger)는
나머지는 다음 조건을 만족한다.
RF와 PRI 데이터의 각 변화 형태에 대해 속성값 조합 (nSW, nDW)의 범위 및 조합 개수는 표 1과 같다. 주기가 길어짐에 따라 D&S 속성값 개수가 최대 주기가 32인 경우에 비해 25에서 302로 크게 증가한 것을 볼 수 있다.
Ⅲ. 분류기 구조
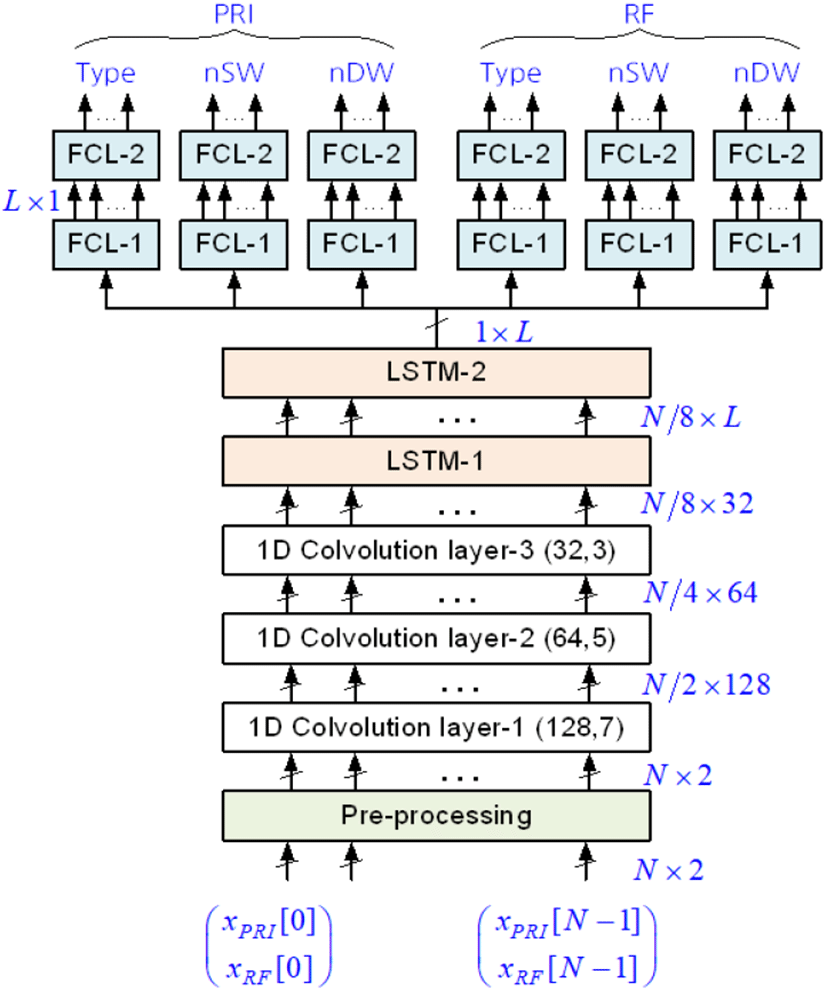
분류기는 PRI와 RF를 동시에 입력하여 각각 Type, nSW, nDW를 분류한다. 분류기는 그림 2와 같이 전처리부를 포함하여 3개의 1차원 가중합층(convolution layer)과 2개의 LSTM 층(CNN-LSTM), 2개의 완전연결층(fully connected layer: FCL)으로 구성된다. 그림에서 NA×NB 표기는 길이 NA 인 NB 차원 벡터를 나타낸다.
3-1 전처리부
심층학습을 적용하는 신경망에서는 많은 계수와 곱 및 합 연산이 수행되므로 입력값을 일정 범위 이내로 제한할 필요가 있다. 따라서 RF와 PRI의 변화 범위를 다음과 같이 정규화한다.
여기서 x[n] 과 x′[n] 은 각각 전처리부의 입력과 출력이고, mX 는 입력의 평균, Δxmax 는 입력 변동치의 최대값을 나타낸다.
분류기의 입력 길이(노드 수)는 성능과 계산량을 절충했을 때 RF 또는 PRI 최대 변화 주기의 4배 정도가 적당하다[9]. 따라서 전처리부의 입력 노드 수는 N=1,024이고, 각 노드는 (PRI, RF) 값 벡터를 입력으로 받아들인다.
3-2 1차원 CNN
1개 가중합층은 필터와 풀링(pooling) 층으로 구성되어 있으며, 필터를 통해 입력 데이터의 특징(feature)을 추출하고 풀링을 통해 압축한다[1]. CNN 3개 층의 필터 개수와 필터 길이는 각각 (128, 7), (64, 5), (32, 3)이고, 모두 필터 출력 2개 중에서 최댓값을 선택하는 MaxPooling을 적용한다. 따라서 첫 가중합층은 1,024개의 벡터 입력을 필터링하여 1,024개의 128×1 벡터를 출력하고, 블록 크기 2인 MaxPooling을 통해 최종적으로 512개의 128×1 벡터를 출력한다. 마찬가지로 제2층은 256개의 64×1 벡터를, 제3층은 128개의 32×1 벡터를 출력한다. 결과적으로 CNN에서는 1,024개의 (PRI, RF) 벡터로부터 원소 수 32인 128개의 특징벡터(feature vector)를 생성한다. CNN의 필터 개수, 필터 길이 등의 내부 파라미터는 모의실험을 통해 결정하였다.
3-3 LSTM 망
LSTM 망은 2개의 LSTM 계층으로 구성되며, 제1층에서는 128개의 32×1 벡터를 입력으로 받아 상태수가 L 인 128개의 벡터를 출력한다. 제2층에서는 상태수 L 인 1개의 벡터를 출력한다. 두 층 모두 출력 노드에서 tanh 함수를 활성함수(activation function)로 사용한다. 학습 과정에서는 학습 데이터의 편중으로 인해 발생하는 과적합(overfitting)을 방지하기 위해 0.3 비율로 무작위로 계수를 제거한다[4]. 상태수 L 실험을 통해 256으로 결정하였다.
3-4 다중출력 완전연결망
완전연결망은 RF와 PRI 각 속성에 대해 2개의 완전연결층으로 구성되며, LSTM 망으로부터 입력을 받아 분류기 최종 결과인 속성값을 출력한다. 제1층은 L 개의 상태벡터 원소 개수만큼의 입력과 출력 노드 개수를 가진다. 각 출력 노드의 활성함수로는 모두 ReLU(rectified linear unit) 함수를 사용한다.
분류기의 최종 출력인 제2층의 출력은 6개 속성의 속성값을 분류한 것으로, 속성별 출력 노드 수는 표 2와 같다. 즉, PRI 경우 Type 개수는 8, nSW는 1부터 32까지 32개, nDW는 1과 6부터 20까지 16개가 된다. 마찬가지로 RF는 각각 7개, 32개, 16개가 된다. 전체적으로 분류기는 표 1로부터 PRI 443가지 속성값 조합에 대해 RF 412가지를 분류하므로, 443×412= 182,516가지의 속성값 조합을 분류할 수 있다.
| Type | STA | JIT | SIN | ST+ | ST− | TRI | D&S | STG | SUM |
|---|---|---|---|---|---|---|---|---|---|
| Original | 1 | 1 | 27 | 27 | 27 | 27 | 302 | 31 | 443 |
| Adjustment | 750 | 750 | 925 | 925 | 925 | 925 | 1517 | 1650 | 8,367 |
| Ratio (%) | 9.0 | 9.0 | 11.1 | 11.1 | 11.1 | 11.1 | 18.1 | 19.7 | 100 |
Ⅳ. 모의실험 결과
제안한 분류기의 성능은 학습에 의한 수렴 과정과 속성별 식별률을 통해 평가한다. 먼저 학습용 데이터를 생성하여 분류기를 학습시키고, 별도의 평가용 데이터를 통해 식별률을 구한다. 학습용 데이터는 표 3과 같이 발생 빈도가 작은 속성값인 경우, 더 많은 개수를 생성하여, 분류기가 각 속성 출력값에 대해 비교적 균일한 비율로 학습되도록 한다. 여기서 조정값은 각 변화 형태의 nSW와 nDW 발생 빈도를 고려하여 경험적으로 결정하였다. 전체 학습열(1개 학습열은 1,024개의 데이터) 개수는 전체 조정 개수의 합을 45배 한 8,367×45=376,515이다. 학습 데이터는 80 %를 학습용으로, 나머지 20 %를 평가용으로 사용하며, 학습용 80 % 중에서 15 %는 모델 검증용으로 사용한다. 학습 단위(batch size)는 400이다.
| Output | PRI | RF | ||||
|---|---|---|---|---|---|---|
| Type | nSW | nDW | Type | nSW | nDW | |
| Number of output nodes | 8 | 32 | 16 | 7 | 32 | 16 |
분류기 모델은 Python 3.5의 Tensorflow 2.3 라이브러리를 사용하여, 최적화 방법(optimizer)은 'adam' 기법을, 손실함수(loss)는 'sparse_categorical_crossentropy'를, 평가측도 (metircs)는 식별률에 해당하는 'accuracy'를 사용한다. 손실함수에 대한 가중치는 1로 동일하고, 학습 횟수(epoch) 은 400이다.
그림 3은 참고문헌 [9]에서 제시한 2-입력-6출력(i2o6) 분류기 구조(a~c)와 제안방법(d)에 대해, 입력 데이터 길이가 1,024일 때 학습횟수에 따른 PRI nSW 속성의 식별률을 나타낸다. 그림에서 청색 선은 학습 데이터에 대한 식별률을 의미하고, 황색 선은 검증 데이터에 대한 식별률을 의미한다. i2o6 분류기는 1,024개 데이터를 다루기 위해 다양한 형태의 입력을 고려하였다. 입력 형태 1,024×2는 1,024개의 PRI와 RF 데이터 쌍 (PRI, RF)를 2×1 벡터로 하여 1,024개 노드에 입력하는 것을 의미하고, Nnode×2 M은 시간 순서로 (PRI[n], …, PRI[n+M−1], RF[n], …, RF[n+M−1])의 2M×1 벡터를 Nnode개 노드에 입력한 것을 의미한다. 그림을 보면 i2o6 분류기 구조에서는 입력 형태를 변화시켜도 분류기가 안정적으로 수렴하지 않는 것을 알 수 있다. 이에 비해 제안 방법은 초기부터 비교적 안정적으로 수렴한다.
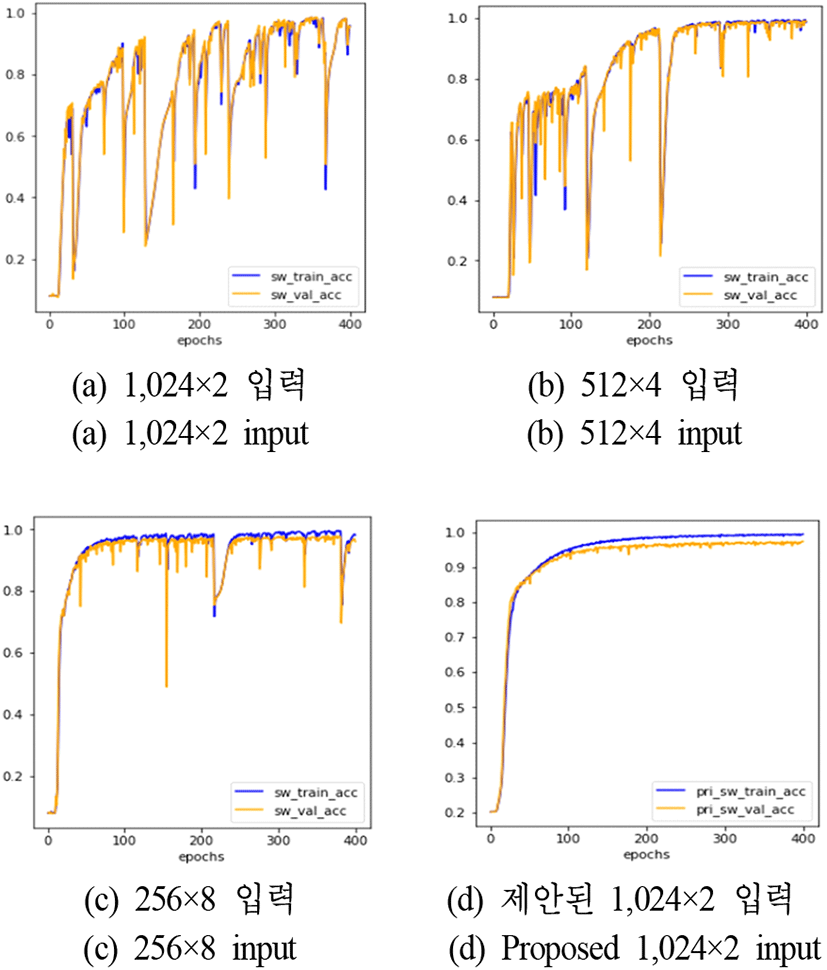
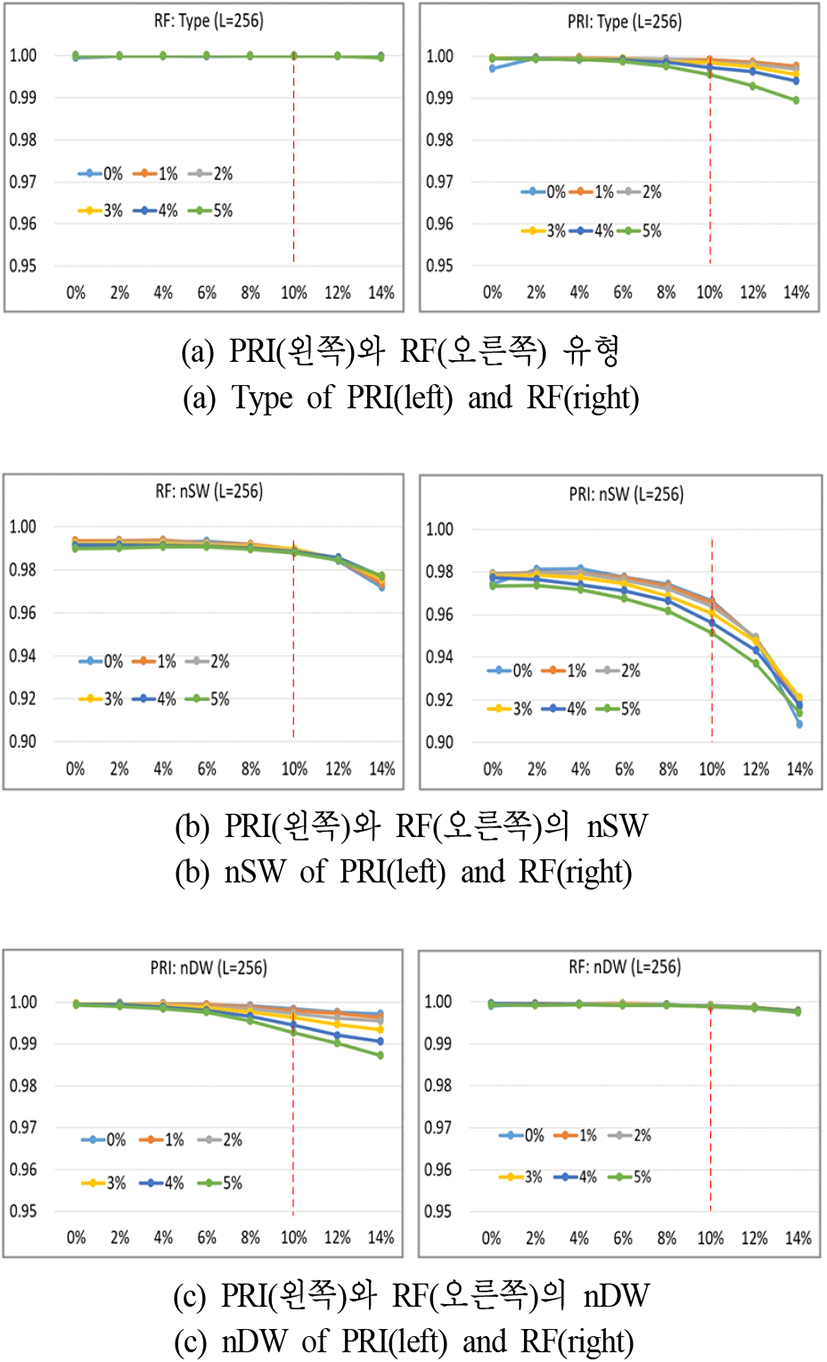
그림 4는 펄스의 누락률과 다른 펄스의 유입률에 따른 제안 방식의 속성별 식별률을 나타낸다. 그림에서 x축은 펄스의 누락률을 나타내고, y축은 식별률을 나타낸다. 색깔별로 표시한 범례는 가짜 펄스의 유입률을 나타낸다. i2o6 분류기 결과와 유사하게 PRI nSW 속성의 식별률이 다른 속성에 비해 낮게 나타난다. 그러나 긴 주기 신호에 대해 i2o6 분류기는 거의 수렴하지 못하는 것에 비해 제시 방법은 최악조건에서도 90 % 이상의 식별률을 나타내는 것을 볼 수 있다.
그림을 보면 펄스의 누락이나 가짜 펄스의 유입에 따라 PRI 식별률이 RF에 비해 더 크게 영향을 받는다. 이것은 펄스의 누락 또는 가짜 펄스의 유입 시 RF는 그 값의 변화가 크지 않지만 PRI는 변화폭이 매우 크게 되기 때문으로 판단된다. 또 PRI, RF 모두 nSW가 Type이나 nDW 속성에 비해 식별률이 낮은 이유는 표 3과 같이 nSW가 분류해야 할 가짓수가 많기 때문이다.
Ⅴ. 결 론
이 논문에서는 CNN과 LSTM 모델을 결합하여 펄스 레이다 신호의 PRI와 RF가 긴 주기를 가질 때 파형을 식별하기 위한 기계학습 방법을 제시하였다. 제시 방법은 PRI와 RF 데이터에 대해 정의된 3개의 속성, 즉 변화 형태(Type), 한 주기 내에서 일정 값을 유지하는 체류 계단 개수(nSW), 한 계단 내에 존재하는 펄스 개수(nDW)를 식별한다. 모의실험 결과 데이터 변화의 특징을 추출하는 CNN을 사용하여 긴 데이터 입력을 압축함으로써 LSTM이 안정적이고 효과적으로 동작하는 것을 확인할 수 있었다.
제시한 벙법은 PRI와 RF의 최대 변화 주기가 256에 이르기까지 전체 182,516가지 속성 조합에 대해 90 % 이상의 식별률을 나타낸다. 일반적으로 실제 환경에서 펄스 누락률이 10 % 이하임을 감안하면 전체적으로 95 % 이상의 높은 식별률을 나타낸다. 한편, 심층학습 구조 분류기에서 학습 데이터의 분포는 식별률에 크게 영향을 미친다. 이 논문에서는 경험적으로 분류 속성별 학습열 개수를 정하였는데, 향후 이를 논리적으로 정량화하는 방법에 대해 연구하고자 한다.




