





Ⅰ. 서 론
레이다(radar)는 전파를 사용하여 특정 목표물까지 거리와 방향, 목표물 크기와 이동 속도 등을 측정하는 전자장치를 말한다[1],[2]. 현대의 전자전에서 미사일이나 유도탄 공격 시 목표물을 탐색하거나 추적하기 위해서 대부분 레이다를 사용하며, 따라서 레이다는 현대전에서 없어서는 안 될 중요한 전자 장비이다. 한편, 적의 이러한 공격을 무력화시키기 위해서는 레이다 전파를 방해해야 하며, 이를 위해서는 먼저 레이다 신호의 특성을 분석하여 레이다 종류를 파악해야 한다[3].
지금까지는 레이다의 종류를 분류하기 위해서 주로 사전에 구축된 신호 특징(feature) 데이터베이스를 이용한다[3]. 레이다 펄스의 특성은 PDW(pulse description words)로 표현된다. PDW의 주요 구성 요소는 도래 시각(time of arrival: TOA), 펄스 반송파의 무선주파수(radio frequency: RF), 펄스 폭(pulse width: PW), 펄스 크기(pulse amplitude: PA), 도래각(angle of arrival: AOA) 등이다[4]. 이 중에서 TOA는 보통 펄스 반복 간격(pulse repetition interval: PRI)을 구하기 위한 기초 데이터로 사용된다[5]. 일반적으로 레이다 신호의 특징 요소를 구하고, 그 특징 요소로 데이터베이스를 조회하여 레이다를 식별한다. 이 경우, 특징 요소의 변화 형태, 반복되는 주기 등을 추정하는 과정을 거치게 된다.
최근에는 PRI, RF 등의 특징 데이터를 직접 기계학습(machine learning)에 적용하여 레이다 자체를 식별하거나 신호를 분류하는 연구들이 많이 수행되고 있다. 기계학습을 적용하면 부가적으로 신호 특성이 데이터베이스에 없는 경우, 가장 유사한 신호 특성을 가진 기존 레이다로 분류하거나, 또는 여러 레이다와의 유사도를 나타낼 수 있는 장점이 있다[4], [6]~[10].
홍석준 등[6]은 위협 레이다 종류를 특정하고, 이에 대응하는 전파 방해 방법을 선택하기 위해 레이다 신호를 분류하는 방법을 제시하였다. 분류기는 레이다 펄스신호의 PRI와 RF 데이터를 CNN(convolutional neural network)에 적용하여 7가지 종류로 레이다를 분류하였다. Bin Wu 등[7]은 표본화된 레이다 신호 자체에 1차원 CNN을 적용하여 RF 변조 형태를 7가지로 분류하였다. Nguyen 등[8]은 PRI 데이터에 CNN을 적용하여 시간에 따른 변화 형태를 7가지로 분류하였다. Notaro 등[9]은 PRI, RF, PW 3개의 특징 데이터를 LSTM(long short-term memory) 망에 적용하여 17종류로 분류하였으며, 이경훈 등[10]은 동일한 방법으로 8종류로 분류하였다.
레이다 또는 레이다 신호를 식별하기 위해 최근에 제시되는 기계학습 방법들은 CNN 또는 RNN(recurrent neural network) 계열의 LSTM을 많이 적용하고 있으며, 일반적으로 시간적 상관 특성을 반영하는 LSTM의 성능이 더 나은 것으로 알려져 있다[4].
한편, 지금까지 제시된 방법들은 대부분 PRI, RF, PW 등의 특징 데이터를 사용하여 레이다 신호를 수 개 또는 수십 개의 레이다 종류나 PRI 또는 RF의 변화 형태로 분류하고 있다. 그러나 식별해야 하는 레이다 종류는 PRI와 RF 변화 형태뿐만 아니라, 반복 주기까지 포함하여 수천 가지 이상 존재한다.
이 논문에서는 레이다 펄스 신호의 PRI와 RF에 대해 3가지 속성(attribute)을 정의하고, 심층학습(deep learning)을 적용하여 그 속성 자체를 분류하는 방법을 제시하고자 한다. 속성은 PRI와 RF 데이터의 변화 형태, 주기당 계단 수, 계단당 펄스 수이며, 전체적으로 22,410가지의 속성 조합을 가진다. 분류기는 LSTM 망을 기반으로 구성된다.
이 논문의 구성은 먼저 II장에서 식별하고자 하는 펄스 레이다 신호의 특성을 설명하고 속성을 정의한다. III장에서는 제안한 LSTM 기반 2개 분류기의 구조 및 분류 방법에 대해 설명한다. IV장에서는 모의실험 결과를 제시하고, V장에서 결론을 맺는다.
Ⅱ. 펄스 레이다 신호의 특성 및 속성
이 논문에서는 레이다 중에서 주로 많이 사용하는 펄스 레이다를 고려한다. 펄스 레이다 신호의 파형은 그림 1과 같이 높은 무선주파수(RF)를 가지는 정현파를 펄스열로 변조하여 포락선이 펄스의 형태를 가지게 된다. 펄스 반복 간격(PRI)은 펄스가 연이어 나타날 때 펄스 사이의 시간 간격을 나타내며, 무선주파수는 중심주파수를 나타낸다. PRI와 RF는 보통 시간에 따라 변하는 값을 가진다. 그림에 표시한 펄스 진폭, 펄스 폭, PRI 및 RF는 각 펄스의 특성을 기술하는 PDW의 주요 성분이다. 이 논문에서는 이 중에서 레이다 특성을 결정하는 주요 요소인 PRI와 RF만을 고려하기로 한다.

PRI와 RF는 시간에 따라 값이 변하는데, 변화 형태에 따라 그림 2와 같이 PRI의 경우 8개의 패턴으로 구분할 수 있다[6]. 그림의 가로축은 펄스 번호를 나타내고, 세로축은 PRI 또는 RF를 나타낸다. RF는 스태거(stagger) 형태가 없어서 7개의 변화 형태를 가진다. 각 그림 위의 제목은 변화 형태 명칭을 나타내는데, 괄호가 없은 것은 PRI, 괄호 안은 RF에 대한 것이다. 지터(jitter)와 스태거는 모두 불규칙하게 변하는데, 지터는 주기가 없고 스태거는 주기적으로 변하는 점만 다르다.
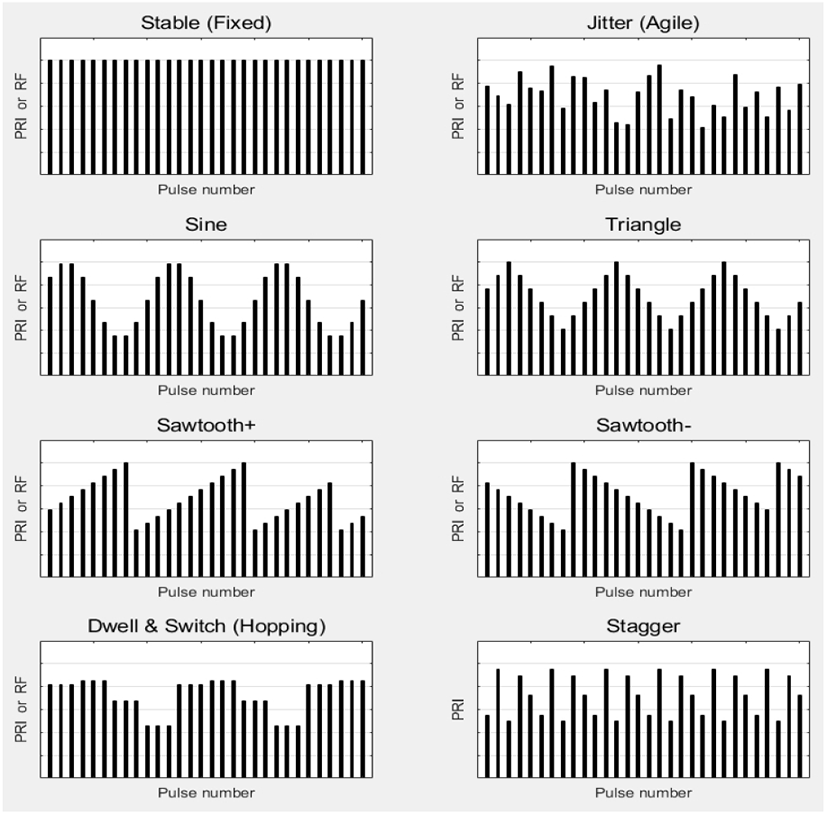
nSW를 주기가 있는 경우, 한 주기 내의 펄스 수 또는 체류(dwell) 기간이 있는 경우, 한 주기 내의 체류 수(계단 수), nDW를 체류 기간 동안의 펄스 수로 정의하면 다음과 같은 관계가 있다.
각 변화 형태에 대해 속성값 쌍 (nSW, nDW)를 지정할 수 있다. 고정 형태(stationary)와 지터는 주기가 없으므로 속성값 nSW를 정할 수 없다. 따라서 (1, 1)로 취급할 수 있다. 체류변경(Type 6)을 제외하고는 모두 nDW는 1이 된다. 변화 형태의 약어와 속성값쌍을 정리하면 표 1과 같다.
이 논문에서는 PRI와 RF 데이터의 변화 형태(Type), 주기당 계단 수(nSW), 계단당 펄스 수(nDW) 등 3개 속성으로 레이다 신호를 식별하고자 한다. 따라서 분류기에서 3개의 속성값 (Type, nSW, nDW)가 희망 출력값이 된다.
변화 형태의 주기는 최소 6에서 최대 32라 가정한다. 즉, D&S(dwell and switch)를 제외한 변화 형태의 속성값 범위는 다음과 같다.
D&S의 속성값 범위는 다음 조건을 만족한다고 가정한다.
PRI와 RF의 각 변화 형태에 대해 속성값 범위 및 (nSW, nDW) 조합의 개수는 표 2와 같다. 전체적으로 PRI는 166개, RF는 135개의 속성값 쌍이 존재한다.
이 논문에서는 PRI와 RF 데이터의 비이상적인 특성으로 측정 오차와 펄스 누락 및 다른 펄스 유입을 고려한다. 측정 오차는 펄스를 검출하고, 이로부터 PDW 성분을 측정 및 추정할 때 발생하는 오차이다. TOA, RF 등의 PDW 데이터를 구하기 위해서는 일반적으로 그림 3과 같이 수신된 레이다 신호를 고속의 아날로그-디지털(analog- to-digital: AD) 변환기를 통해 디지털로 변환하고, 이어서 표본의 신호처리를 통해 펄스 검출, PDW 데이터 추정, 펄스 분리 등의 과정을 거친다[11]. 이때 표본화 간격이 유한하고 또 잡음이 유입되기 때문에 TOA, RF 등을 추정할 때 측정 오차가 발생한다.
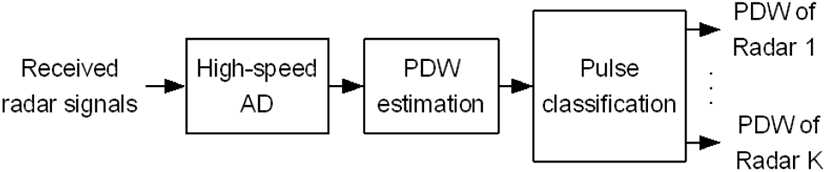
펄스 누락과 다른 펄스 유입은 여러 레이다로부터 수신된 펄스를 레이다별로 분류하는 과정에서 발생한다. 일반적으로 수신기에는 여러 레이다 신호가 동시에 수신될 수 있다. 따라서 그림 3과 같이 펄스마다 추정한 PDW 데이터를 다시 펄스 진폭, 스캔 형태, 스캔 주기, 펄스 폭, 주파수 등에 따라 레이다별로 분류하는 과정을 거친다. 이때 펄스가 겹치거나 분류 오류 등에 의해 특정 레이다에 대한 펄스가 누락되거나 또는 다른 레이다 펄스가 유입될 수 있다.
그림 4는 측정 오차, 펄스 누락, 다른 펄스 유입 등 비이상적인 특성이 반영된 경우, PRI와 RF 변화 형태의 예를 나타낸다. 그림에서 보면 펄스 누락과 유입에 대한 영향이 PRI 변화 형태에서 더 뚜렷한 것을 알 수 있다.
Ⅲ. LSTM 기반 분류기
PDW 데이터 중에서 PRI(TOA로부터 계산함)와 RF는 레이다 신호 식별에 가장 중요한 요소이다[10]. 이 장에서는 PRI와 RF를 사용하여 변화 형태(type), 주기당 계단 수(nSW), 계단당 펄스 수(nDW)를 식별하기 위한 두 가지 형태의 분류기를 제시한다.
단일입력 분류기는 PRI 또는 RF 데이터 입력에 대해, Type, nSW, nDW 등 3개 속성값을 분류한다. 즉, 1개 입력에 대해 3개 출력(i1o3)을 가진다.
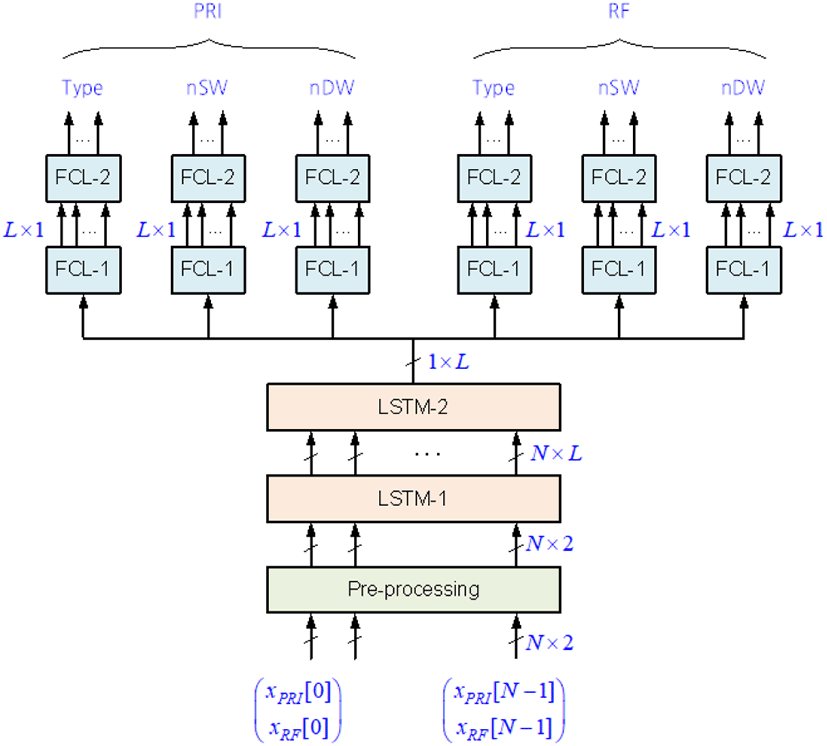
분류기는 그림 5와 같이 전처리기, 2개의 LSTM 계층, 3개 지로(branch)로 분리된 2개의 완전연결층(fully connected layer: FCL)으로 구성된다. 3개 지로인 완전연결망은 모두 동일한 구조를 가진다.
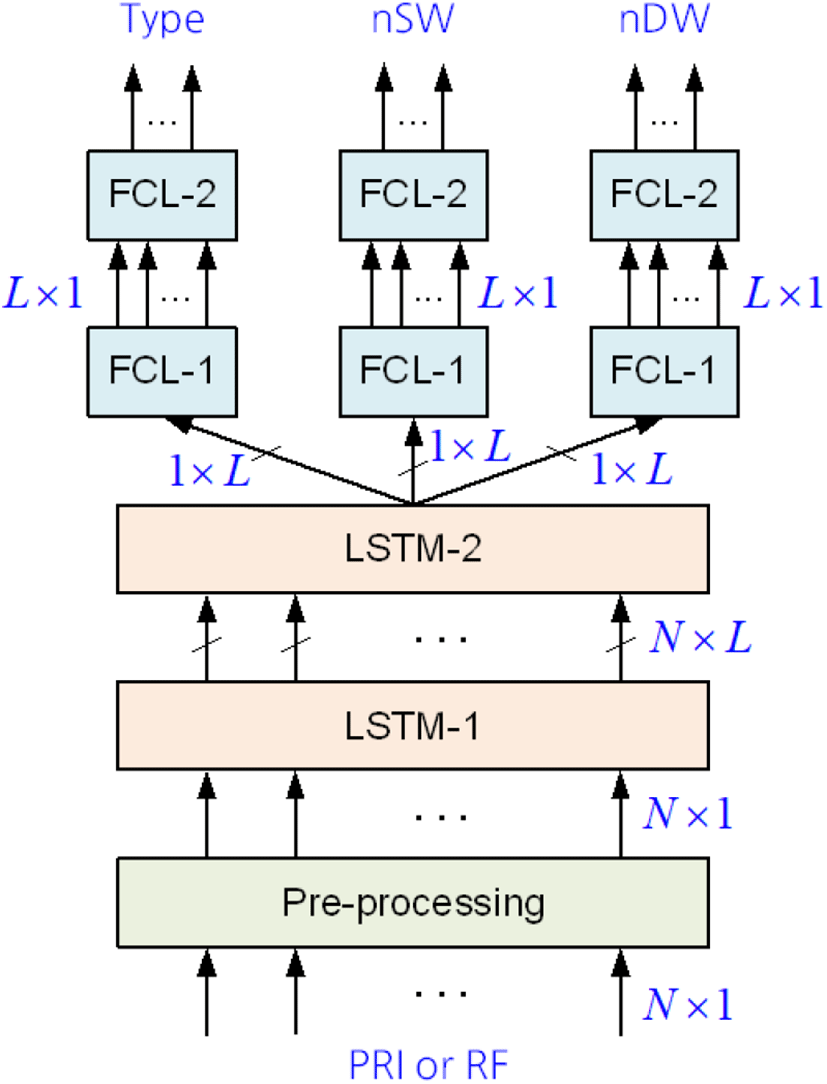
분류기의 입력은 N 개의 원소(즉, 입력 노드의 개수)로 구성된 PRI 또는 RF 단일 벡터이다. 여기서 N 은 편의상 PRI 또는 RF의 최대 주기로 가정한 32의 정수배로 놓는다.
각 출력 노드의 개수는 분류하고자 데이터의 종류 및 속성의 개수에 따라 달라지며, 표 2로부터 구하면 표 3과 같이 된다. 분류 가짓수는 표 2로부터 PRI 분류기는 166개가 되고, RF 분류기는 135개가 된다.
| Outputs | PRI | RF | ||||
|---|---|---|---|---|---|---|
| Type | nSW | nDW | Type | nSW | nDW | |
| Number of outputs | 8 | 32 | 7 | 7 | 28 | 7 |
심층학습을 위해서는 입력이 일정 범위 이내의 값을 가지도록 해야 하는데, 전처리기가 이런 역할을 수행한다. 일반적으로 PRI와 RF 값의 평균값과 변화 형태에 따른 변동 범위는 레이다에 따라 크게 달라진다. 특히 PRI는 평균값이 수 μs에서 수 ms까지 1,000배 이상의 변동성을 가진다. PRI와 RF는 그림 3의 수신 펄스 분류 과정에서 이미 레이다별로 분류하므로, 절대적인 평균값과 변동 범위에 따른 레이다 정보는 이미 결정되었다고 가정해도 무방하다. 따라서 세부 식별 과정에서는 데이터의 평균값을 제거하고, 변동 범위를 일정 크기로 제한하여 사용한다.
PRI와 RF의 변동 범위는 평균값에 따라 다르므로, 정규화된 출력 x′[n]은 다음과 같이 되도록 한다.
여기서 mX는 PRI와 RF 데이터의 평균을 나타내고, α 는 mX에 대한 최대 변동 비율을 나타낸 것으로 이 논문에선 0.2를 적용한다. 이 값은 PRI와 RF 변화 범위를 평균값의 20 % 이내로 제한했기 때문에 편의상 놓은 값으로, 상수곱에 해당하기 때문에 분류기 성능에 미치는 영향은 없다.
2개의 LSTM 계층 중에서, 제1층은 N 개의 입력 노드와 출력 노드로 구성되며, 각 노드는 차원(즉 상태 수)이 L 인 상태벡터이다. 제2층은 1층의 출력 노드로부터 입력을 받아 1개의 노드로 출력한다. 이 때 출력 노드는 1층과 동일하게 L 차원의 상태벡터이다. 2개 계층은 모두 각 출력 노드에서 tanh 함수를 활성함수(activation function)로 사용한다[12].
2개의 완전연결층이 LSTM 층으로부터 입력을 받아 최종 출력을 낸다. 제1층은 LSTM의 상태 개수만큼의 입력과 출력 노드 개수를 가진다. 따라서, L × L 개의 계수로 구성된다. 제1층의 각 출력 노드는 활성함수로 ReLU (rectified linear unit) 함수를 사용한다[12].
제2층은 L × M (M 은 출력 노드 수)개의 계수로 구성된다. 각 출력 노드의 활성함수는 0~1 사이의 값을 나타내고, 확률과 유사한 특성을 가지는 SoftMax 함수이다[12]. 제2층의 출력은 분류기의 최종 출력이 된다.
분류기의 복잡도 또는 계산량은 전체 계수의 개수로 나타낼 수 있다. 표 4는 N=160, L=128 , 출력의 개수가 8(PRI의 Type 수)인 경우, 각 계층 및 전체 분류기의 계수 개수를 나타낸다.
이중입력 분류기는 PRI와 RF 2개 입력에 대해, PRI와 RF 각각의 3개 속성, 즉 6개 속성을 출력(i2o6)한다. 분류기의 구조는 그림 6과 같다. 단일입력(i1o3) 분류기와 비교했을 때, 입력부가 2원소 벡터로 바뀐 점과 출력부 완전연결망이 6개 지로로 분기된 점이 다르다. 각 완전연결망의 출력 노드 수는 PIR, RF에 따라 달라지며, 앞의 표 3과 같다.
이 분류기는 표 2에 나타낸 바와 같이 PRI, RF 각각 166, 135개의 가짓수를 분류한다. 결과적으로 6개 출력을 가진 이중입력 분류기의 분류 가짓수는 166×135=22,410개가 된다.
Ⅳ 모의실험 결과
제안한 3개 형태의 분류기 구조의 성능을 살펴보기 위해 먼저 학습 및 평가용 데이터를 생성한다. 학습용 데이터는 평가용 데이터와는 분리된 것으로, 분류기를 학습시키기 위한 용도로만 사용한다. 학습을 마친 후 평가용 데이터를 사용하여 분류기의 성능을 평가한다. 성능 평가 척도로는 정확하게 분류한 비율인 식별률을 사용한다.
PRI 및 RF 데이터는 변화 형태를 포함하여 표 2와 같이 각각 166, 135개의 속성을 가진다. 따라서 생성해야 할 데이터열의 가짓수는 표 5와 같이 PRI와 RF 각 속성의 조합이 된다. 앞으로 이를 "기본조합"이라 부르기로 한다. 기본조합의 가짓수는 22,410개가 된다.
학습용 데이터는 분류기 성능이 최적화되도록 생성해야 한다. PRI와 RF 속성값의 기본조합을 나타내는 표 5를 살펴보면 PRI의 변화 형태 STA(stationary)와 JIT(jitter), RF의 변화 형태 FIX와 AGL(agile) 속성값의 가짓수가 다른 변화 형태에 비해 현저하게 적은 것을 알 수 있다. 이 경우, 기본조합의 가짓수에 비례하는 학습 데이터를 사용하여 분류기를 학습시키면, 상대적으로 학습되는 횟수가 작은 속성의 경우 식별률이 낮아지게 된다[13]. 따라서 PRI와 RF의 각 속성에 대해 확률적으로 균형을 이루도록 조합의 개수를 표 6과 같이 조정하였다. 앞으로 이를 “학습용 조합”이라 부르기로 한다.
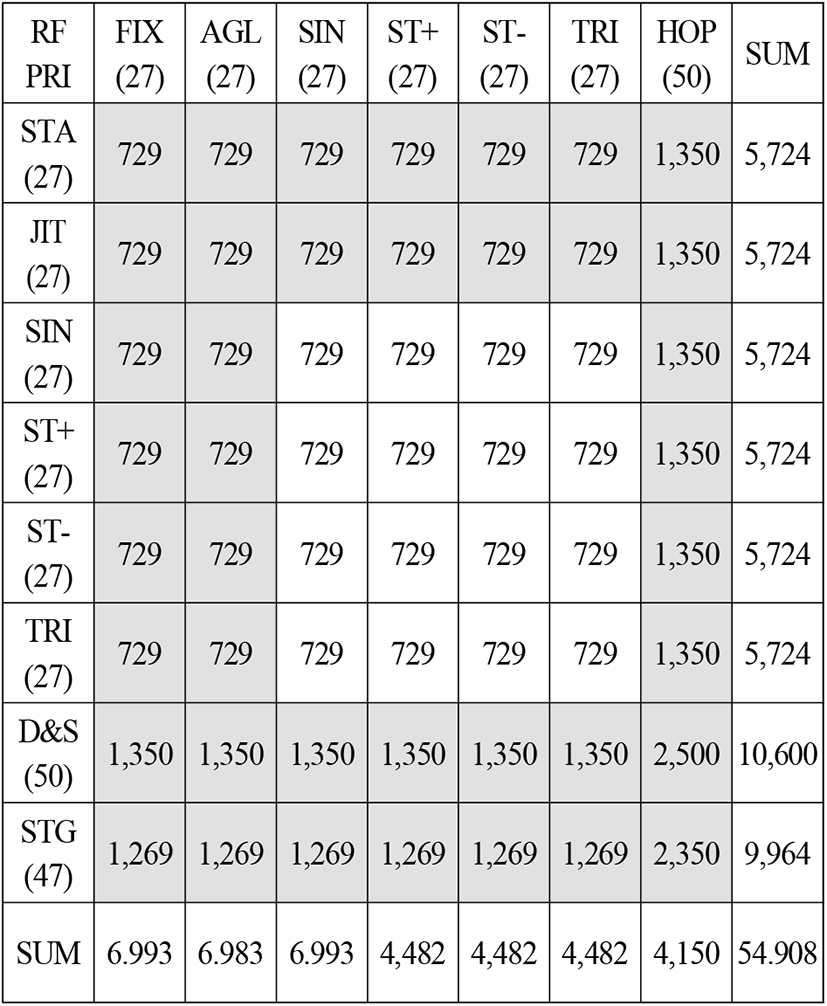
학습용 조합에서는 PRI의 STA와 JIT, RF의 FIX와 AGL을 모두 1에서 27로 늘렸다. D&S는 nSW가 1이 아닌 유일한 형태이기 때문에 상대적으로 nDW를 학습시킬 수 있는 가짓수가 적다. 따라서 생성 개수를 2배로 확대하였다. PRI STG(stagger)의 경우는 nSW가 2~5에 해당하는 값이 다른 변화 형태에서는 존재하지 않기 때문에 균형을 맞추기 위해 4배 늘려 31에서 47로 늘렸다.
전체 학습용 데이터열의 개수는 학습용 조합의 8배를 생성한다. 즉
학습용 데이터는 비이상적 특성도 반영하여 생성한다. 측정 오차는 평균값의 0~1 % 사이에서 균일분포를 가지도록 불류칙적으로 선택하여 반영한다. 또한 펄스 누락률은 0~10 % 사이에서 선택하며, 다른 펄스 유입율은 0~5 % 사이에서 균일하게 선택하여 반영한다.
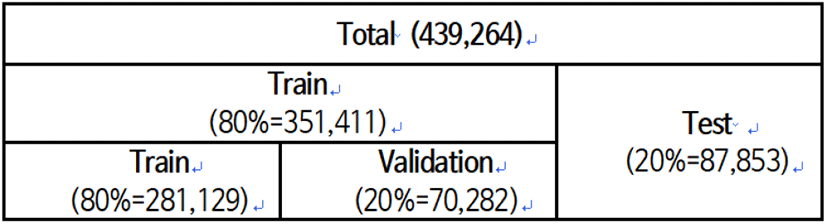
전체 439,264개의 학습용 데이터열은 불규칙적으로 섞은 후, 그림 7과 같이 80 % : 20 %로 나누어 훈련(train)과 시험(test)에 사용한다. 80 %의 훈련용 데이터는 다시 80 % : 20 %로 나누어 각각 순수 훈련용과 훈련 검증용으로 사용한다. 훈련 검증용은 모델의 파라미터를 선택하고 최종 모델을 결정하기 위한 것이다. 또, 학습시킨 모델이 훈련 데이터에 과적합(overfitting)되는 것을 방지하기 위해서도 필요하다. 시험용 데이터는 학습을 통해 결정된 모델의 성능을 평가하기 위한 용도로 사용된다. 실제 각 속성에 대한 성능 평가는 별도로 생성된 평가용 데이터를 적용하여 수행한다.
평가용 데이터는 각 속성 및 펄스 누락률, 다른 펄스 유입률 등에 대한 식별률을 구할 수 있도록 학습용 데이터와는 별도로 생성한다. 각 속성값이 모두 포함되고, 분포가 균일하도록 표 6의 학습용 조합 개수만큼 데이터열을 생성하여 이로부터 식별률을 구한다.
제안한 3개의 분류기 구조에 대해 먼저 모델 파라미터(hyperparameter)에 해당하는 LSTM의 상태 개수(L)와 입력 개수(N)를 결정하기 위한 학습 및 평가를 수행한다. 상태 수와 입력 수를 결정한 후, 다시 학습을 통해 최종적으로 분류기의 파라미터를 결정한다. 분류기의 성능 평가는 다른 펄스 유입률을 0 %부터 5 %까지, 펄스 누락률을 0 %에서 14 %까지 변화시켜가며 생성된 평가용 데이터를 사용하여 식별률을 구하는 방법으로 수행한다.
그림 8은 에 따른 LSTM의 상태 개수에 따른 분류기의 식별률을 나타낸다. 그림을 보면 여러 속성 중에서 PRI의 주기당 계단 수(nSW)가 다른 속성에 비해 성능이 현저하게 떨어지는 것으로 나타났다. 이것은 분류해야 하는 가짓수가 상대적으로 많기 때문이다. PRI의 nSW를 보면 상태 수가 128일 때 식별률이 가장 크고, 그보다 작거나 큰 경우는 모두 식별률이 감소한다. 따라서 상태 수는 128로 고정하였다.
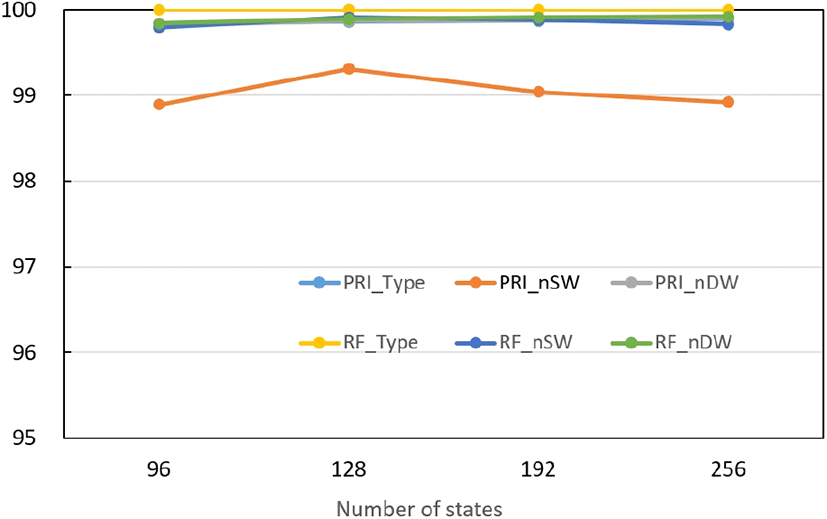
그림 9는 상태 수를 128로 놓은 경우, 입력 개수에 따른 PRI와 RF 각 속성의 식별률을 나타낸다. 그림에서 보면 다른 속성에 비해 주기당 계단 수(nSW)의 성능이 많이 떨어지는 것을 볼 수 있다. LSTM 모델의 전체 파라미터 개수는 입력 개수에 비례하여 증가한다. 그림으로부터 구조의 복잡도와 성능을 절충하여 입력의 개수는 160으로 정하였다.
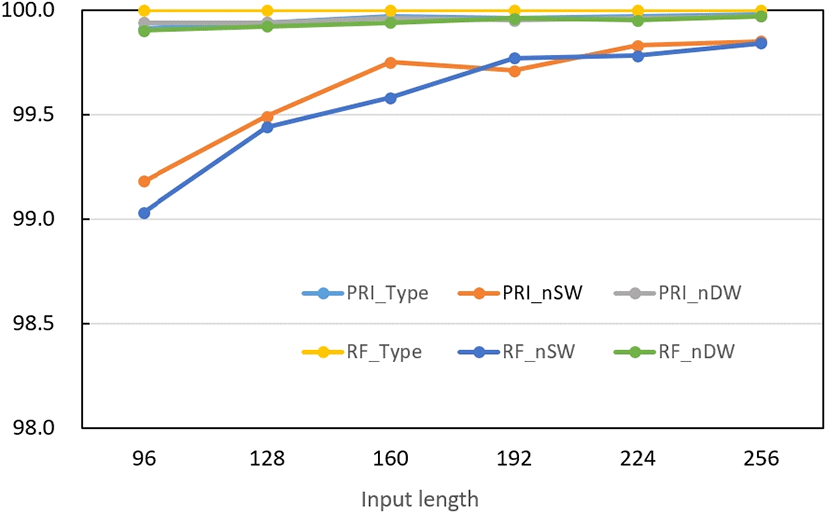
상태 수와 입력 수를 32의 배수에 대해 성능을 구한 것은 데이터열의 한 주기가 최대 32이기 때문이며, 단순히 편의상 정한 값이다.
그림 10은 PRI와 RF의 속성인 Type, nSW, nDW 분류 결과를 나타낸다. 그림에서 가로축은 펄스 누락률을, 세로축은 식별률을 나타내며, 각 곡선은 다른 펄스 유입율을 0~5%까지 다르게 하며 나타낸 것이다. 식별률은 펄스 누락률과 다른 펄스 유입률이 증가함에 따라 점차 저하되지만, 한 주기당 계단수(nSW)를 제외하면 최악의 조건에서도 모두 99.5 % 이상의 식별률을 나타낸다.
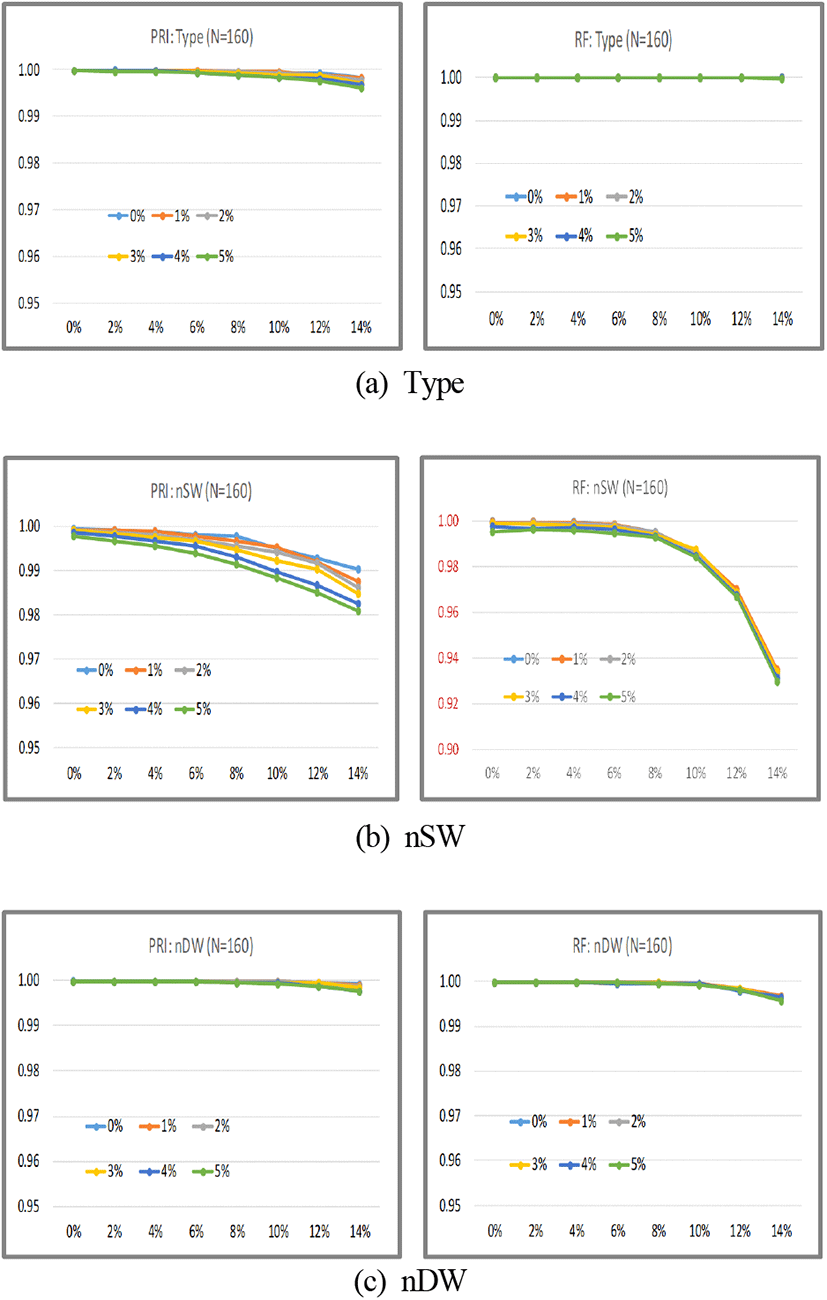
nSW는 PRI, RF 모두 다른 속성에 비해 성능이 떨어진다. 이것은 표 3과 같이 nSW의 가짓수가 Type이나 nDW에 비해 훨씬 많기 때문이다. 한편, 누락률이 클 때 RF의 nSW는 PRI에 비해 식별률이 훨씬 더 낮다. 이것은 펄스 누락과 다른 펄스 유입의 영향이 PRI 데이터열에는 시간 간격으로 반영되지만 RF 데이터열에는 반영되지 못하기 때문으로 판단된다. 즉 펄스 누락 시 PRI의 경우에는 갑자기 큰 값이 나타나므로 이상 현상(outlier)으로 취급되어 그 영향이 무시될 수 있지만, RF의 경우에는 주기당 계단 수가 한 개 줄어든 것으로 인식될 수 있다. 다른 한편으로 PRI의 nSW는 다른 펄스 유입과 펄스 누락이 식별률에 미치는 영향은 비슷하지만, RF의 경우는 펄스 누락이 더 큰 영향을 미치는 것을 볼 수 있다.
이중입력 분류기는 단일입력 분류기와 입력이 다른 구조를 가진다. 그러나 모의실험 결과 LSTM의 상태 수와 입력 수에 대한 결과는 단일입력 분류기와 유사한 경향을 보여 L=128, N = 160으로 동일하게 놓았다.
그림 11은 PRI와 RF의 Type, nSW, nDW의 분류 결과를 나타낸다. 모의실험 최악 조건에서 전체적으로 97.5 % 이상의 식별률을 나타낸다.
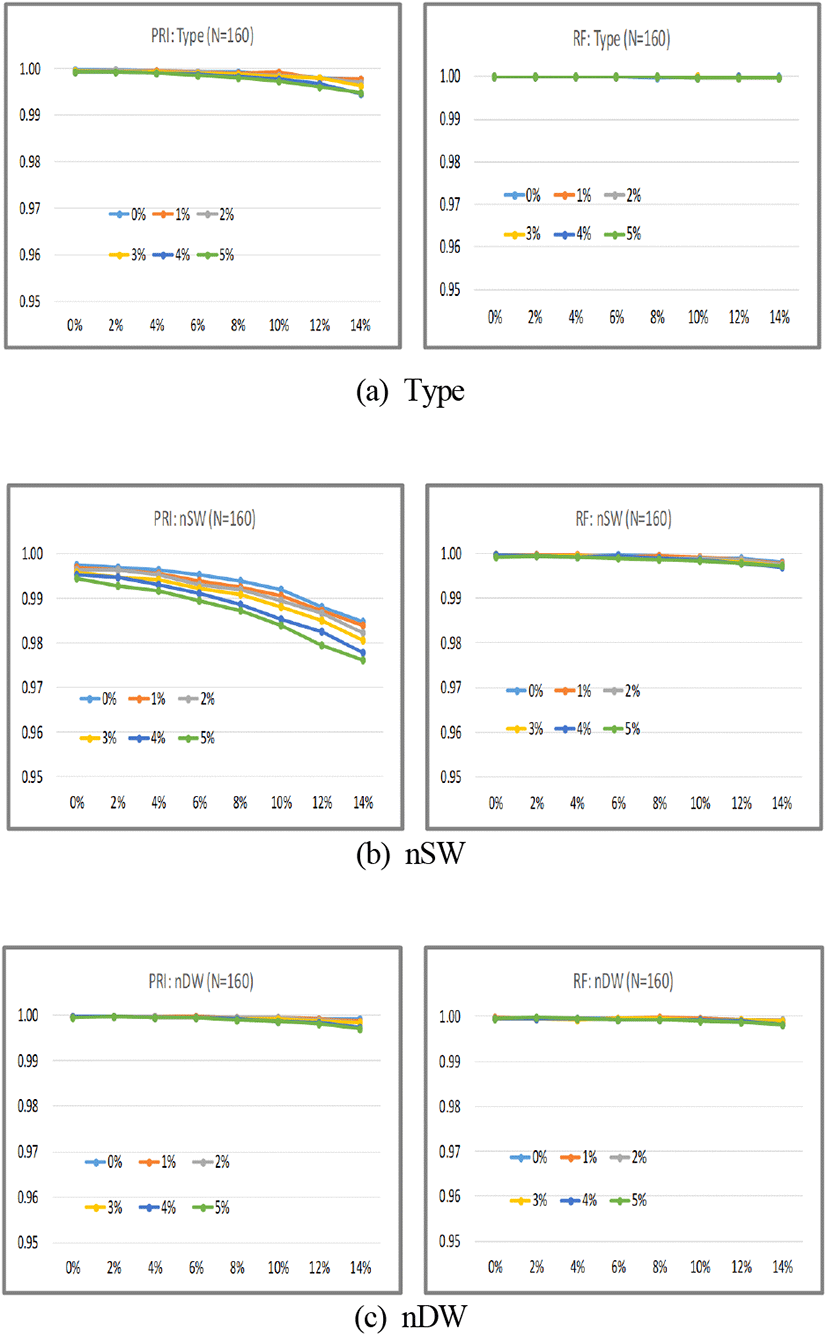
그림을 보면 PRI의 nSW만이 다른 속성에 비해 식별률이 훨씬 낮다. 또, 단일입력 분류기와 다르게 RF와 PRI의 nSW 식별률 특성이 뒤바뀐 것을 알 수 있다. 이것은 최악 조건에서 두 분류기에 대해 입력 수에 따른 nSW의 식별률을 나타낸 그림 12를 보면 더 명확하게 알 수 있다. PRI는 분류기 구조에 따른 성능의 차이는 크지 않다. 그러나 RF는 단일입력인 경우에 비해 이중입력인 경우, 분류기 성능이 크게 향상된다. 구조에 따른 이러한 성능 차이는 두 데이터 PRI와 RF의 상관성 때문으로 판단된다. 펄스가 누락되거나 유입될 때 그림 4의 예와 같이 PRI 값은 크게 영향을 받지만 RF 값은 영향이 크지 않다. 이런 특성 때문에 심층학습 과정에서 PRI는 큰 변화량에 의해 RF에 정보를 전달할 수 있지만, RF는 변화량이 크지 않아 PRI에 정보를 많이 전달해 주지 못하게 된다.
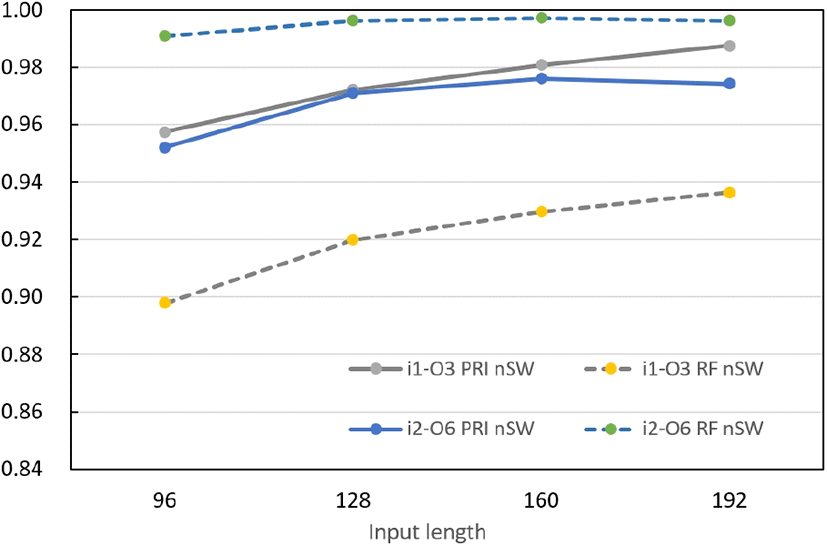
그림 12를 보면 모의실험 최악조건에서 단일입력 분류기는 입력 수를 증가시킴에 따라 식별률이 약간씩 증가하지만 160 전후로 증가율이 둔화되고 있고, 이중입력 분류기의 경우는 160 이후로 더 이상 향상되지 않는다. 이로부터 계산량을 고려하여 두 분류기의 입력 길이를 160으로 선택한 것이 모의실험 최악조건에서도 부적합하지 않았음을 알 수 있다.
Ⅴ. 결 론
이 논문에서는 LSTM 모델을 기반으로 기계학습을 적용하여 펄스 레이다 신호의 PRI와 RF를 각각 3개의 속성에 따라 분류하는 3개 구조의 분류기를 제시하고, 그 성능을 살펴보았다. 3개 분류기는 PRI의 nSW를 제외한 PRI와 RF의 모든 속성에 대해 i1o1 < i1o3 < i2o6 순으로 식별률이 향상되었다. i2o6 분류기는 모의실험 최악 조건에서 3개 속성 Type, nSW, nDW 모두에 대해 97.5 % 이상의 식별률을 나타내었으며, 분류 가짓수가 많은 nSW를 제외하면 99 % 이상의 높은 분류 정확도를 나타내었다. 이러한 성능은 입력의 수가 최대 주기의 5배 정도면 충분함을 나타낸다.
이 논문에서 제시한 분류기는 레이다 신호의 PRI와 RF의 변화 형태와 주기당 계단 수, 계단당 펄스 수 등의 속성값 자체를 분류한다. 따라서 i2o6 분류기의 경우, 6가지 속성을 동시에 분류하므로 최대 22,410가지의 특성을 분류할 수 있다. 제시한 방법은 더 세밀하게 레이다 신호를 분류함으로써 위협 레이다에 대응하기 위한 재밍 기법 등에서 더 정밀하게 대응할 수 있을 것으로 기대된다.




