
Ⅰ. 서 론
현재 민간 서비스 영역에서의 5G 이동 및 무선통신, IoT (Internet of Things) 등 다양한 종류의 신규 무선 서비스의 출현으로 향후 모바일 트래픽 이용량은 더욱 빠르게 증가할 것으로 예상되고 있으며, 군 무선통신 또한 첨단화 및 다양화되는 무기체계 출현 및 주파수 소요의 확대로 추가 주파수 획득이 점차 어려워지고 있는 실정이다[1],[2]. 이에 주요 선진국을 중심으로 이동간(OTM) 통신이 요구되는 전술통신환경에서 한정된 자원인 주파수를 지능적, 효율적으로 이용하여 무전기의 기동성, 생존성, 유연성을 보장하기 위한 스펙트럼 관리 기술에 대한 연구가 지속적으로 진행되고 있으며, 네트워크 중심전(NCW)의 대표적인 핵심 요소 기술로서 CR(Cognitive Radio) 엔진 기술이 연구되고 있다[3].
본 논문은 CR 엔진을 구성하는 ‘학습엔진’ 및 ‘추론엔진’에서 보다 효과적인 가용채널 추론과 데이터베이스에 주기적으로 저장 및 갱신되는 간섭보호가 필요한 인컴번트 사용자(incumbent user)의 무선 채널 별 점유확률 정보를 이용한 기계학습 알고리즘 기반의 무선 트래픽 이용환경 추론기법을 제안하였다. 이를 위해 학습엔진 데이터베이스에 저장되어 있는 기존 인컴번트 사용자의 트래픽 이용정보를 기반으로 신규 이용자의 미래 가용채널 정보 추론을 위하여 기계학습의 일종인 SVM(Support Vector Machine) 기법을 적용하였다[4]. 이를 통해 모든 채널별 트래픽 정보 각각에 대해 추론 과정을 수행을 통하여 최상의 채널 추론결과를 제공하는 ‘Exhaustive search’ 방법 대비 본 논문에서 제안하는 SVM 기법과 k-NN 기법과의 성능비교를 통하여 트래픽 모델 추정에 대한 추론 정확도 및 시간 복잡도에 대한 성능비교를 수행하였다[5].
본 논문의 2장에서는 CR 엔진의 전체 구성 및 역할에 대해 소개하였다. 또한 인컴번트 사용자의 트래픽 모델 생성과정 및 학습엔진에 저장되는 인컴번트 사용자의 채널 점유확률 변화에 따른 트래픽 모델 종류 및 생성과정에 대해 소개하였다. 3장에서는 SVM 기법에 대한 기본개념 및 특징, 트래픽 모델 추론에 있어서의 적용방안에 대해 소개하였다.
4장에서는 인컴번트 사용자의 채널 점유확률 변화에 따른 트래픽 이용 모델 추론기법의 성능분석을 위한 모의실험 절차 및 결과를 나타내었으며, 마지막으로 5장에서는 본 논문의 결론을 맺고자 한다.
Ⅱ. CR 엔진의 구성 및 역할
그림 1은 본 논문에서 소개하는 CR 엔진의 기본 구조에 대해 나타내고 있으며, 표 1은 CR 엔진을 구성하는 개별 엔진들에 대한 기능을 나타내고 있다.
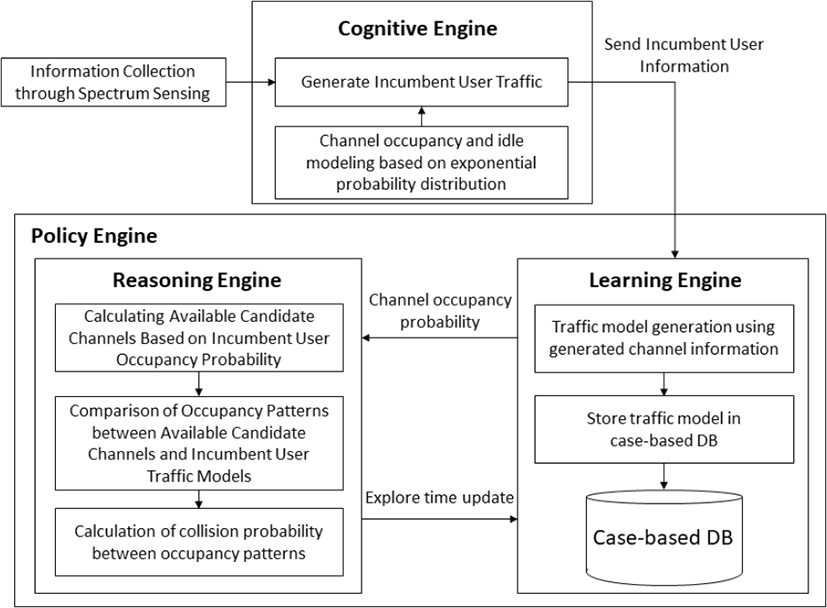
본 논문에서 소개하는 사례기반 추론 기법을 이용한 CR 엔진은 크게 인지엔진, 학습엔진, 추론엔진으로 이루어져 있다[6]. 인지엔진에서는 스펙트럼 센싱을 통해 새로운 트래픽이 발생하였을 때 해당 채널 이용패턴 정보를 수집한다. 학습엔진은 인지엔진에서 수집된 채널 이용정보를 바탕으로 트래픽 모델을 생성 후 해당 정보를 이용하여 정책수립을 위한 추론과정의 의사결정 근거가 되는 정보를 사례기반 DB에 분류하여 저장한다. 추론엔진에서는 학습엔진에서 구축한 사례기반 DB를 활용하여 신규 이용자의 채널 이용정보와 가장 유사한 사례를 검색하여 해당 사례에 적합한 해결책인 추론주기와 가용 후보채널의 개수를 제공하고, 해결책의 분류 및 저장 과정을 수행한다.
그림 2는 학습 및 추론엔진에서 이루어지는 전반적인 처리과정에 대한 전체적인 처리 과정도를 나타내고 있다.
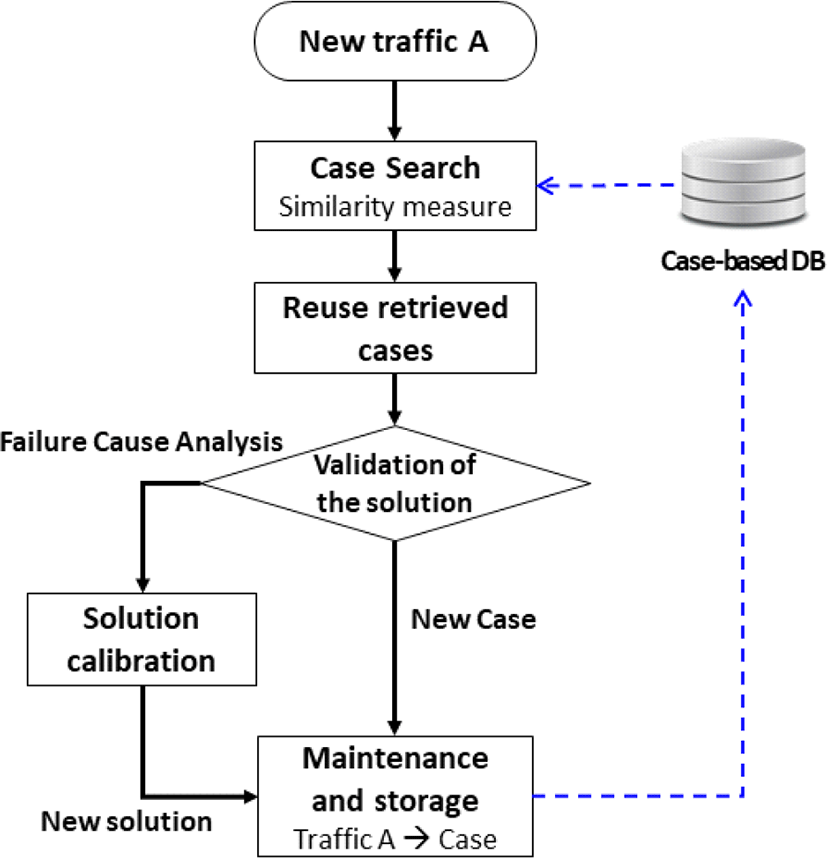
스펙트럼 센싱을 통한 신규 트래픽 A가 발생하면 새로운 트래픽 A와 사례기반 DB에 저장되어 있는 트래픽 모델 간 유사도 검증을 통한 가장 유사한 사례의 검색을 수행한다. 가장 유사한 사례가 검색되면 해당 사례의 트래픽 모델이 갖고 있는 채널 이용정보를 새로운 트래픽 A의 상황에 적용한다. 해당 해결책을 적용하여 신규 사용자와 인컴번트 사용자의 충돌확률이 25 % 이내를 만족시키면 유지 및 저장 단계로 넘어가고, 해결책의 적용이 실패하였다면 충돌확률 25 % 이내를 만족시키는 추론주기 및 가용 후보채널의 개수를 찾아 해당 해결책이 올바르게 적용되도록 교정한 다음, 유지 및 저장 단계로 넘어간다. 충돌확률 기준은 CSMA/CA 기반의 802.11 무선랜 환경에서 6개 이내의 무선랜 노드가 존재하였을 때의 일반적인 충돌확률 값을 가정하였다[7]. 유지 및 저장 단계에서는 올바르게 적용된 해결책을 사례기반 DB에 저장하고 분류한다.
본 논문에서는 사례 검색에서의 새로운 트래픽과 사례기반 DB에 저장된 트래픽 모델 간 유사도 검증 과정과 유지 및 저장에서의 트래픽 모델의 클래스 별 분류 과정의 계산량을 줄여 더욱 효율적인 처리를 할 수 있도록 기계학습을 적용하였다.
본 논문에서는 스펙트럼 센싱을 통한 채널 이용정보 수집을 대신하여 가상의 인컴번트 사용자 채널 이용정보를 모델링하기 위해 지수 확률분포 기반의 트래픽 이용 모델링을 생성하였다. 채널별 인컴번트 사용자의 채널점유 상태를 on(busy)과 off(idle) 상태 중 하나라고 가정하고, 채널의 on/off 상태변화는 지수 확률분포를 따라 변화한다.
인컴번트 사용자의 n번째 채널의 ON/OFF 상태인 구간에 대한 평균값을 로 정의한다. 인컴번트 사용자의 전체 채널 점유확률의 평균값을 이라 하고, 의 값을 조절하여 인컴번트 사용자의 채널 이용상태를 식 (1)을 통하여 제어할 수 있다[8].
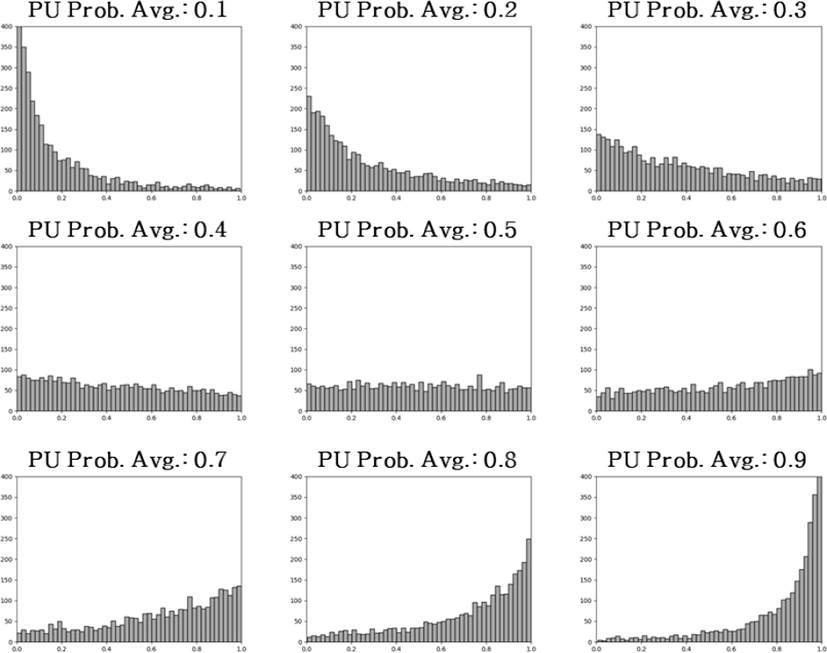
트래픽 모델은 인지엔진에서 스펙트럼 센싱을 통하여 얻은 점유패턴의 정보와 학습엔진에서의 학습과정을 통해 생성된 해당 점유패턴에 대한 정책정보를 포함하여 사례기반 DB에 저장된다. 그림 3은 인컴번트 사용자의 단위 시간 슬롯 당 채널 미점유 및 점유상태를 기반으로 전체시간 슬롯에 대한 채널별 평균 점유확률 변화에 따른 트래픽 모델 생성결과를 나타내고 있다.
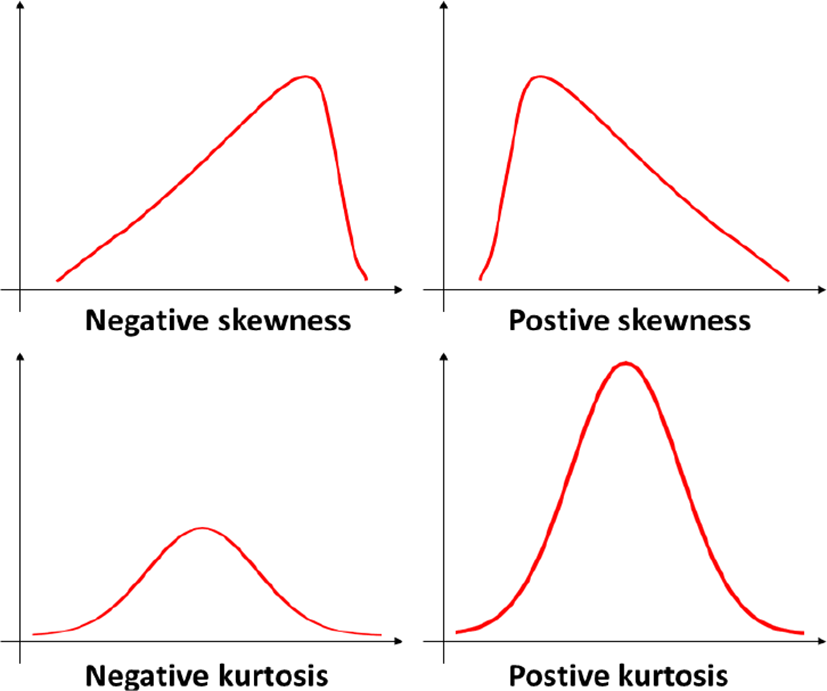
본 논문은 새로운 점유패턴과 유사한 사례의 히스토그램을 검색하기 위한 매칭 파라미터로서 히스토그램의 왜도 값과 첨도 값을 사용한다. 여기서 왜도는 히스토그램의 비대칭성 정도를 나타내는 지표이며, 첨도는 히스토그램의 정규분포 대비 얼마나 뾰족한지에 대한 정도를 나타내는 지표이다. 그림 4에서 볼 수 있듯이 히스토그램의 왜도 값이 커질수록 히스토그램의 형태가 오른쪽에서 왼쪽방향으로 치우치고, 첨도 값이 커질수록 히스토그램의 높이가 높아짐을 확인할 수 있다.
Ⅲ. 기계학습을 이용한 트래픽 모델 추론
본 논문은 기계학습의 분류 알고리즘 중 하나인 SVM을 적용하여 인컴번트 사용자의 무선 트래픽 추론과 분류 및 저장 과정을 수행하였다. SVM은 그림 5에서 볼 수 있듯이 두 개의 클래스로 나뉜 데이터들을 분류하는 최적의 결정경계(Decision Boundary)를 찾는 것이 목적이다. SVM은 결국 각 클래스(yi)와 훈련 데이터(x)의 학습을 이용해 최적의 초평면(hyperplane)인 결정경계를 정의할 수 있는 법선벡터(w)와 bias를 찾는 것이 목표이며, 그 식은 식 (2)와 같다. 단, 식 (3)을 만족하여야 클래스 별 분류에서 더욱 정확한 분류가 가능하다.
SVM을 이용한 클래스 분류에서 현재 차원 데이터의 선형적인 분리가 불가능할 경우, 커널트릭(Kernel trick)을 이용하여 데이터를 고차원으로 매핑 후 선형적으로 분리할 수 있다. 즉, 매핑된 고차원에서 데이터의 내적을 구하면 선형적으로 분리는 가능해지지만 연산량이 증가하게 된다. 이러한 문제를 해결하기 위해 고차원 매핑함수와 동등한 함수인 커널함수를 사용하면 연산량 감소와 함께 고차원에서의 선형적 분류와 같은 결과를 얻는 것이 가능하다. 본 논문에서는 다양한 커널함수 중 대표적인 함수인 Linear, RBF(Radial Basis Function), polynomial, sigmoid 각 함수별 추론성능 비교를 수행하였다.
| Kernel | Kernel function expression |
|---|---|
| Linear | |
| RBF | K(x1,x2)=exp(−γ‖x1-x2‖2) |
| Sigmoid | |
| Polynomial |
본 논문의 그림 3과 같이 히스토그램으로 표현된 다양한 형태의 인컴번트 사용자 트래픽 이용 패턴을 고려할 때, 2개 이상의 클래스 분류가 필요하므로 SVM을 이용한 이진분류는 불가능하다. 이러한 문제는 여러 클래스의 데이터들을 이진분류기를 적용 가능한 다수의 상황으로 분할 후 다시 합치는 Multi-class SVM 방식으로 해결할 수 있다[9]. 이러한 Multi-class 문제를 해결하기 위한 기법으로는 OvO (One-vs-One) 방법과 OvR(One-vs-Rest) 방법이 존재한다.
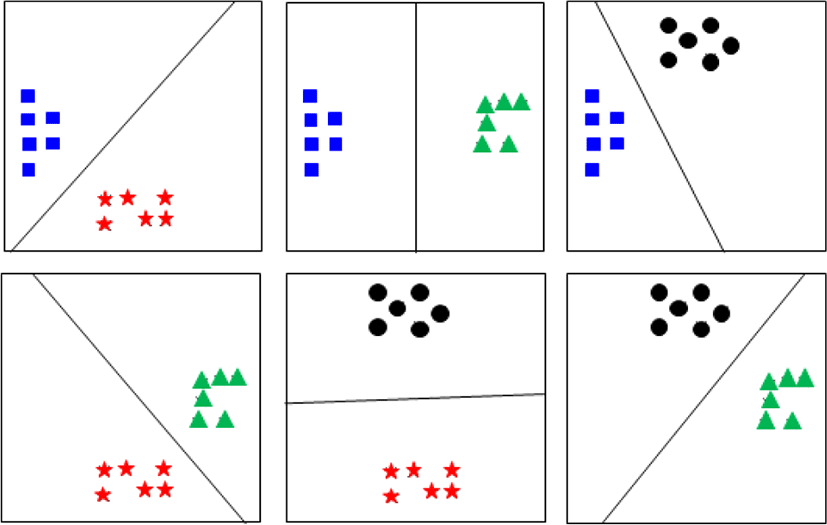
그림 5의 OvO 방법은 m개의 클래스가 존재하는 경우, 2개의 클래스 조합을 선택하여 m(m-1)/2개의 이진분류 문제를 풀고 판별식을 통해 가장 높은 판별 값을 얻은 클래스를 선택하는 방법이다.
그림 6의 OvR 방법은 m개의 클래스가 존재하는 경우, 개별 클래스에 다른 표본들이 속하는지, 속하지 않는지에 대한 이진분류 문제를 m번 풀어 판별식을 통해 판별 값이 높은 클래스를 선택한다.
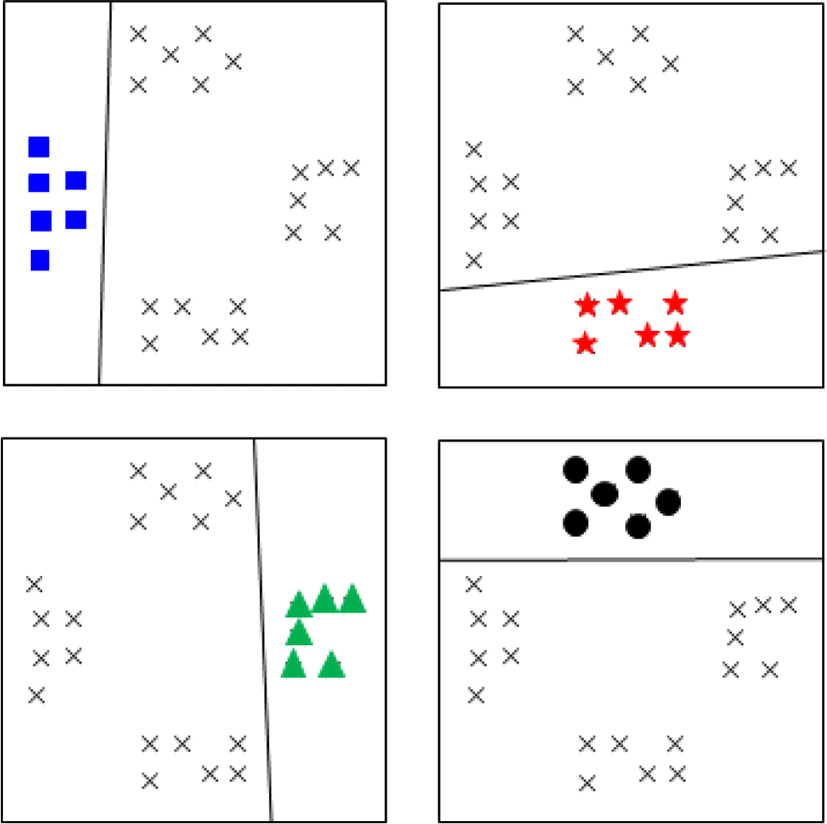
본 논문은 트래픽을 이진분류가 아닌 점유확률 별 5개의 다중 클래스로 분류하였기 때문에 클래스의 수가 많을 경우에는 OvO 방법에 비해 계산량이 적은 OvR 방법을 적용한 Multi-class SVM 기법을 이용하였다.
Ⅳ. 모의실험
본 장에서는 기계학습을 적용한 트래픽 모델 추정에 대한 추론 성능분석을 위해 모의실험을 수행하였다. 그림 7은 본 모의실험의 전체적인 처리 과정을 나타내고 있다.
즉, 학습엔진 사례기반 DB에 저장되어 있는 각 트래픽 모델 히스토그램의 매칭 파라미터인 왜도, 첨도 값을 2차원 그래프 상에 나타낸 후 SVM을 적용하여 점유확률별 클래스의 영역으로 나눈다. 갱신된 채널 히스토그램의 왜도, 첨도 값이 어느 클래스영역에 속하는지 SVM을 이용하여 예측하면 해당 채널과 가장 유사한 환경의 트래픽모델을 유추할 수 있다.
본 모의실험 dataset 중 사례기반 DB에 저장되어 있는 training set은 본 논문 2-3절의 지수 확률분포 기반 채널 이용정보 모델링을 통해 가상의 인컴번트 사용자 트래픽 모델 1,300개를 생성하였다. Test set 또한 본 논문 2-3절의 지수 확률분포 기반 모델링을 통해 새롭게 갱신된 채널의 트래픽 모델 500개를 생성하였다.
그림 8는 본 모의실험에서 SVM 커널함수를 이용한 트래픽 모델 분류에 대한 결과를 나타내고 있다.
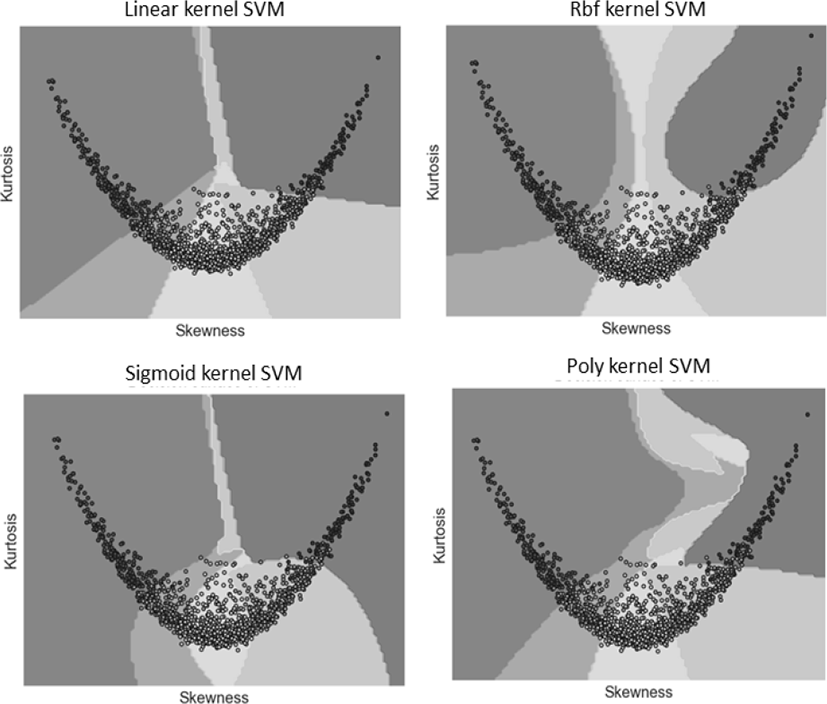
그림 8의 모의실험 결과에서 알 수 있듯이 SVM을 이용한 트래픽 추론은 SVM 커널 함수별로 데이터의 분류방식이 다르므로 커널에 따른 성능이 달라질 수 있다. 그러므로 본 논문에서는 SVM 커널 별 성능을 측정하기 위해 SVM의 가장 대표적인 커널함수인 Linear, RBF, Sigmoid, Polynomial 함수 간 예측정확도에 대한 성능비교를 수행하였다.
표 3은 갱신된 채널 500개를 예측했을 때, 저장된 트래픽모델 데이터 개수의 변화에 따른 추론 정확도를 커널함수 별로 측정했을 경우의 모의실험 결과를 나타내고 있다.
표 3의 결과를 통해 알 수 있듯이 SVM을 사용한 예측은 저장된 트래픽 모델이 100개 이하인 경우에는 75 % 정도의 예측 성능을 보이며, 트래픽 모델이 1,000개 이상인 경우에는 90 % 이상의 높은 예측성능을 보이는 것을 알 수 있다. 커널별 성능을 비교해 보면 트래픽 모델의 수가 적을 때는 Polynomial 커널이 가장 높은 추론 정확도를 보였고, 트래픽모델의 수가 Dataset의 수와 비슷한 정도인 500개를 넘어설 때부터는 Sigmoid 커널이 평균적으로 좋은 성능을 보인 것을 알 수 있다. 전체적인 추론 정확도의 평균을 보면 Linear 커널이 87.58 %, RBF 커널이 87.68 %, Sigmoid 커널이 87.43 %, Polynomial 커널이 87.62 %이므로 RBF 커널이 전체적으로 가장 우수한 추론 정확도를 보이는 것을 알 수 있다.
본 논문에서는 SVM의 객관적인 추론 성능을 평가하기 위하여 기계학습의 분류 알고리즘 중 특징 공간 내 입력 데이터를 k개의 근접 이웃 데이터 클래스 중 과반수의 클래스에 할당하는 방식으로 분류를 수행하는 k-NN(k-Nearest Neighbor)과 SVM의 트래픽 모델 추론 성능비교를 수행하였다. 본 실험에서 SVM은 평균적으로 가장 추론성능이 좋았던 RBF 커널을 사용하여 성능비교를 진행하였다.
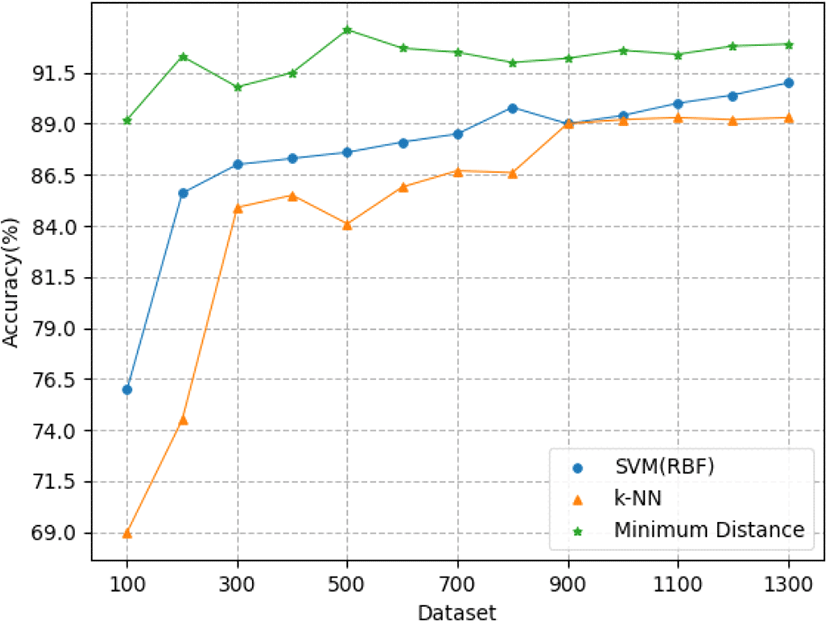
그림 9는 SVM과 k-NN 간의 트래픽 모델 추론 성능비교를 수행한 모의실험 결과를 나타내고 있다. 본 모의실험 결과에서 minimum distance 방법은 새로운 데이터가 하나 갱신되었을 때, 나머지 모든 데이터와의 유사도를 검증하여 가장 유사한 데이터를 찾는 exhaustive search 방식이므로 각 상황에서 보일 수 있는 가장 높은 예측 정확도의 기준이 되는 방식이다. 데이터의 수가 적을 때는 SVM과 k-NN 방법 모두 dataset을 500개 고려할 경우 추론 정확도는 minimum distance 방법의 90 %보다 5 % 낮은 85 % 정도의 정확도를 보이지만, 데이터의 수가 1,000개 이상으로 증가할수록 SVM과 k-NN 방법 모두 minimum distance 방법과 유사한 90 % 이상의 추론 정확도를 보이는 것을 알 수 있다. 또한 기계학습 간 비교를 통해 RBF 커널을 사용한 Multi-class SVM 방법이 k-NN 방법에 비해 대부분의 구간에서 더 높은 추론 정확도를 보이는 것을 알 수 있다.
기계학습의 트래픽 추론 문제를 해결하는데 소요되는 시간의 객관적 비교를 위해 본 논문에서는 기계학습 간의 시간 복잡도 비교를 수행하였다. 각 알고리즘의 시간 복잡도는 Big-O 표기법을 사용하여 나타내었다. 본 실험에서는 사전 데이터 학습 과정에서의 시간 복잡도는 고려하지 않고 새로운 데이터의 추론 과정에서의 시간 복잡도 비교를 수행하였다.
SVM의 추론은 비선형 SVM 분류를 시행하였을 때 예측할 데이터가 속한 영역만을 파악하면 되므로 해당 영역의 가장자리에 위치한 데이터인 서포트벡터의 값들만 알면 데이터의 영역 예측이 가능하다. 또한 시간 복잡도는 O(Nsv+d)로 나타낼 수 있으며, 여기서 Nsv는 서포트 벡터의 총 개수, d는 클래스의 개수를 의미한다[10].
k-NN의 예측은 예측할 데이터와 주변의 k개의 이웃데이터를 비교하기 때문에 시간 복잡도는 O(n log(k))로 나타낼 수 있으며, n은 예측할 데이터의 개수, k는 k값을 나타낸다[11].
Minimum distance의 예측은 예측 데이터와 모든 데이터의 유사도 검증을 수행하는 exhaustive search 방식이기 때문에 O(n log(n))의 시간복잡도로 나타낼 수 있다. 그림 10의 모의실험 결과는 SVM과 k-NN의 Big-O 표기법을 이용한 시간 복잡도 비교결과를 나타내고 있다.
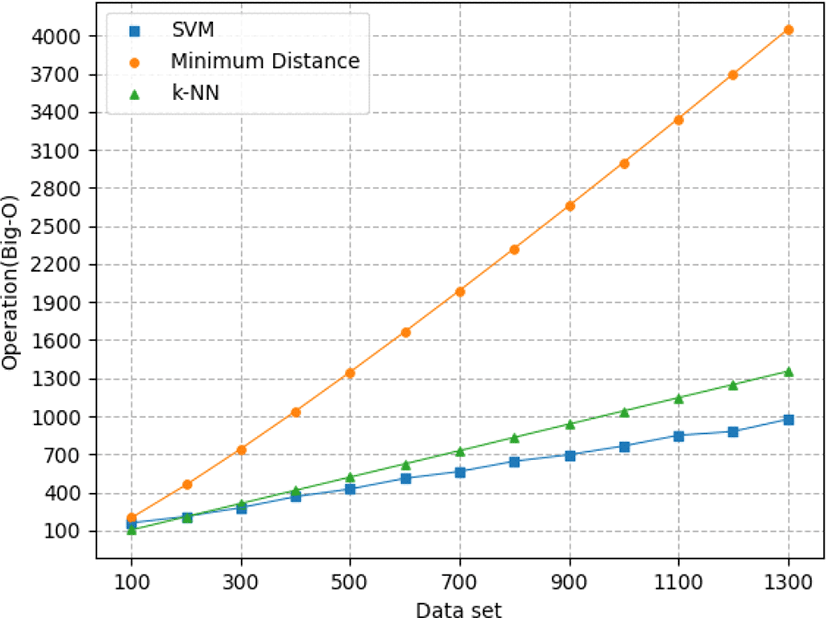
그림 10의 모의실험 결과에서 알 수 있듯이 SVM과 k-NN 모두 exhaustive search 방식인 minimum distance 방식에 비해 시간 복잡도가 적은 것을 알 수 있다. 또한 기계학습 간의 비교를 수행하면 데이터가 200개 이하의 적은 경우에는 k-NN의 시간 복잡도가 적은 것을 알 수 있고, 데이터가 200개 이상인 경우에는 SVM의 시간복잡도가 적은 것을 알 수 있다.
Ⅴ. 결 론
본 논문은 주기적인 센싱을 통해 인컴번트 사용자의 채널 이용상태 정보가 갱신되었을 경우, 해당 채널 이용상태 정보와 가장 유사한 트래픽 모델을 추론하는데 있어 기계학습의 대표적인 분류 알고리즘 중 하나인 SVM을 이용하였다.
본 논문의 모의실험 결과에서 알 수 있듯이 사례기반 데이터베이스의 데이터가 500개 이하로 적을 때는 기계학습의 추론 성능이 exhaustive search 방식의 경우보다 낮은 정확도를 보였지만, 데이터가 1,000개 이상으로 많아질수록 기계학습이 추론 정확도의 지표인 exhaustive search 방식에 근사한 정확도를 보이는 것을 알 수 있었고, k-NN에 비해 SVM이 평균적으로 좋은 추론 정확도를 보이는 것도 알 수 있었다.
시간복잡도 검증 측면에서는 기계학습 모두가 exhaustive search 방식에 비해 우수한 성능을 보이는 것을 확인 하였으며, 데이터가 200개 이하로 적은 경우를 제외하고는 SVM의 시간복잡도가 전체적으로 적은 것을 확인할 수 있었다.
모의실험 결과, SVM을 이용한 트래픽 모델 분류 및 추론이 데이터의 수가 1,000개 이상으로 증가할수록 exhaustive search 방식에 근사한 추론 정확도를 보이며 기존보다 더욱 빠른 처리속도로 인컴번트 사용자 무선 트래픽 이용환경의 추론 수행이 가능할 것으로 기대된다.






